実験ツール
概要と主要な概念
実験ツールは、さまざまな入力を使用したモデルの実行と結果の収集を自動化するツールです。実験ツールを使用するために、1つ以上ジョブを構成します。ジョブは、シナリオ(モデル入力のセット)を生成し、実行する各シナリオの複製の数を決定するための戦略を定義したものです。ジョブを実行すると、各シナリオの複製ごとに1回ずつモデルが実行され、その結果を結果データベースファイルに記録されます。結果は、[パフォーマンスの測定]ウィンドウに表示して調査することができます。
2種類のジョブがあります。1つの種類は実験ジョブと呼ばれており、もう1つの種類は最適化ジョブと呼ばれています。両方の種類の複数のジョブを設定できますが、実験ツールを使用できるのは1つのジョブだけです。実験ジョブを使用すると、シナリオのセットとシナリオごとに実行する複製の数を指定することができます。最適化ジョブを使用すると、目標を指定することができます。その目標の最適化を試みるシナリオが自動的に生成されます。
詳細については、「実験についての主要な概念」トピックだけでなく、「ジョブの実行」トピックも参照してください。
少なくとも1つのジョブを実行したら、[パフォーマンス測定結果]ウィンドウを使用して結果データベースファイル内のデータを表示できます。
[ファイル]エリア
[ファイル]エリアは、実験ツールウィンドウの各タブの上にあります。結果データベースファイルのパスを表示して編集したり、ファイルを削除したりできます。[ファイル]エリアには、次のプロパティが表示されます。

結果データベースファイル
このフィールドには、結果データベースファイルへのパスが表示されます。指定されたファイルが存在しない場合は、次のジョブの実行時に作成されます。[デフォルトパスを使用]チェックボックスがオフになっている場合は、このフィールドを使用して、結果データベースファイルのカスタムパスを指定できます。
デフォルトパスを使用
結果データベースファイルのカスタムパスを指定するには、このチェックボックスをオフにします。このチェックボックスがオンになっている場合は、パスがモデルのファイルパスと名前に一致します。
結果ファイルを削除
このボタンをクリックすると、存在する場合に結果データベースファイルが削除されます。ファイルの削除は共通タスクであり、最後のジョブの実行以降にモデルが変更された場合に実行して、複数のモデルからの結果の混合を避ける必要があります。
結果を表示
1つ以上のジョブを実行した場合は、このボタンをクリックして[パフォーマンス測定結果]ウィンドウを開き、結果を表示します。[パフォーマンス測定結果]ウィンドウには、どのジョブによって結果が生成されたかに関係なく、結果データベースファイル内のすべての結果が表示されます。
[ジョブ]タブ
[ジョブ]タブを使用すると、実験ツールでジョブを追加、削除、並べ替え、および編集することができます。このタブの左側では、ジョブのリストを表示して編集することができます。このビューの右側では、選択したジョブを編集することができます。
[ジョブ]タブの左側には、次のプロパティが表示されます。
ジョブ
| アイコン | 説明 |
|---|---|
 |
ジョブを追加します。ジョブは追加後に構成することができます。 |
 |
ジョブを複製します。 |
 |
選択されたジョブを削除します。 |
  |
選択されたジョブをリスト内で上下に移動します。 |
実験ジョブを選択した場合は、[ジョブ]タブの右側に次のプロパティが表示されます。
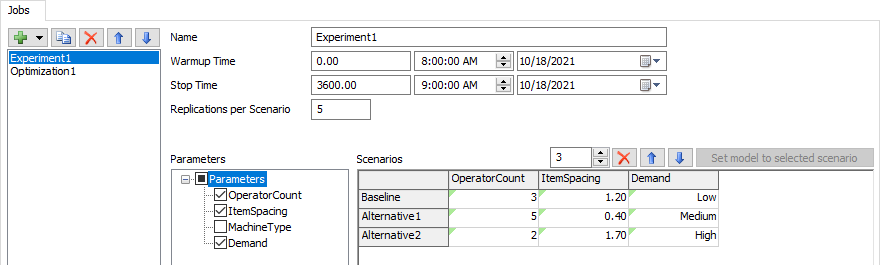
名前
[名前]フィールドを使用して、現在のジョブの名前を更新します。
ウォームアップ時間
[ウォームアップ時間]フィールドを使用して、各シナリオのウォームアップ時間を設定します。
停止時間
[停止時間]フィールドを使用して、各シナリオの停止時間を設定します。
シナリオごとの複製
このフィールドを使用して、シナリオごとに実行する複製の数を設定します。
パラメータ
[パラメータ]ツリーを使用して、[シナリオ]テーブルに表示するパラメータを選択します。他のすべてのパラメータは、すべてのシナリオに対する現在の値のまま残されます。ツリー内のチェックボックスをオンにすると、そのパラメータが[シナリオ]テーブルに列として追加されます。
シナリオカウント
[シナリオ]テーブルの上にある[シナリオカウント]フィールドを使用して、このジョブによって定義されるシナリオの数を指定できます。シナリオを追加または削除すると、[シナリオ]テーブル内の行が追加または削除されます。
削除/上へ/下へ
[削除]/[上へ]/[下へ]ボタン は、[シナリオ]テーブル内の選択されたシナリオを削除または並べ替えます。
選択したシナリオにモデルを設定
このボタンは、テーブル内の単一行を選択すると使用可能になります。このボタンをクリックすると、モデル内のパラメータがその列内の値に設定されます。
[シナリオ]テーブル
このテーブルを使用して、各シナリオ内の各パラメータの値を設定します。
最適化ジョブを選択した場合は、[ジョブ]タブの右側に次のプロパティが表示されます。
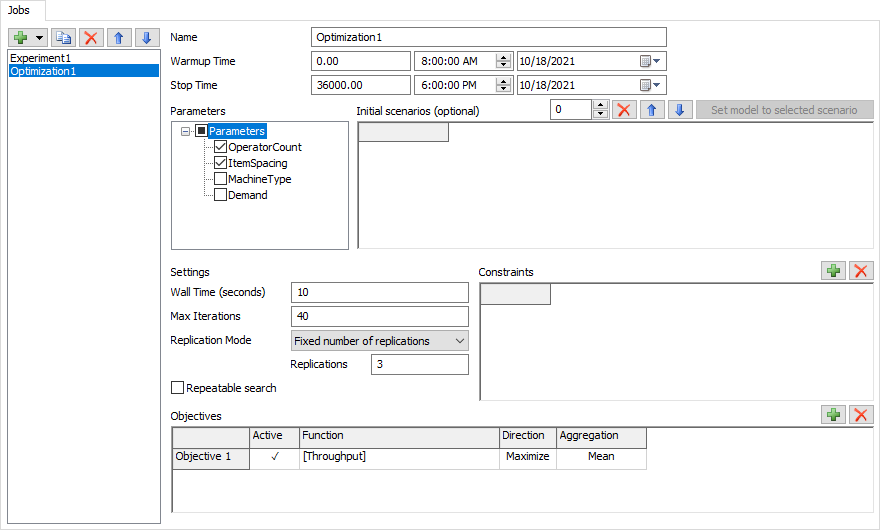
名前
[名前]フィールドを使用して、現在のジョブの名前を更新します。
ウォームアップ時間
[ウォームアップ時間]フィールドを使用して、各シナリオのウォームアップ時間を設定します。
停止時間
[停止時間]フィールドを使用して、各シナリオの停止時間を設定します。
パラメータ
[パラメータ]ツリーを使用して、オプティマイザーで変更可能なパラメータを選択します。他のすべてのパラメータは、最適化中に現在の値のまま残されます。
初期シナリオ
実験ジョブと同様に、実行するジョブのシナリオを定義できます。これらのシナリオはオプションです。これらのシナリオを定義すると、オプティマイザーにその検索の開始点を渡すことができます。これらを定義しなかった場合は、オプティマイザーが独自のアルゴリズムを使用して検索を開始します。
これらのシナリオの定義は、実験ジョブのシナリオの定義と同じです。詳細については、「実験ジョブ」セクションを参照してください。
実測時間
このプロパティは、最適化ジョブが実行するおおよその秒数を指定します。10分後に最適化を自動的に停止するには、600の値を使用します。何らかの他の停止条件が発生するまで最適化ジョブを実行するには、0の値を使用します。
最大反復数
このプロパティは、検索を終了する前に試すシナリオの最大数を指定します。何らかの他の停止条件が発生するまで最適化ジョブを実行するには、0の値を使用します。
複製モード
このプロパティは、最適化ジョブが複製を実行する方法を決定します。このモードには、次の3つのオプションがあります。
- 複製の固定数 - ジョブが生成したシナリオごとに同じ数の複製を実行することを示します。このモードを使用する場合は、シナリオごとに実行する複製の数を指定します。
- 目的の信頼度を達成 - ジョブは、すべての目標について特定の信頼度が達成されるまでシナリオごとに複製を実行する必要があることを示します。あるシナリオがランダム変動の影響をより多く受ける場合は、そのシナリオにはより多くの複製が必要です。このモードを使用する場合は、到達する信頼度を指定します。
- 最適外部信頼度 - あるシナリオが最適なシナリオから統計的に異なることが判明したらすぐに、ジョブがそのシナリオの複製の実行を停止することを除いて、[目的の信頼度を達成]と同様です。
繰り返し検索可能
検索を反復可能にする場合に、このチェックボックスをオンにします。反復可能な検索では、シナリオの同じシーケンスが生成されます。そのため、最適化の時間が長くなる可能性があります。このチェックボックスがオフになっている場合は、シナリオのシーケンスが、実行する各複製にかかる時間によって異なります。
制約
このテーブルを使用して、任意の制約を指定できます。制約は、trueでなければならない式です。最適化ジョブは、制約に違反するシナリオの生成を回避しようとします。
式には、任意のパラメータまたはパフォーマンス指標の名前を含めることができます。有効な例を以下に示します。
[PerformanceMeasure1] <= 1000[PerformanceMeasure2] >= 50[Param1] + [Param2] <= 10行ヘッダーを使用して、制約の名前を設定できます。
目標
このテーブルを使用して、1つの以上のジョブの目標を定義できます。目標は次の4つのコンポーネントで構成されます。
- アクティブフラグ - アクティブな目標のみが最適化で使用されます。
- 関数 - 関数は値を計算する式です。多くの場合、関数は単なるパフォーマンス指標の値です。関数の目的は、モデルのスコアを生成することです。任意のパラメータまたはパフォーマンス指標を使用できます。
- 方向 - 方向は、関数の特定の意味を示します。方向が最大化の場合は、高い関数値を生成するシナリオが最適化において追求されます。方向が最小化の場合は、低い関数値を生成するシナリオが最適化において追求されます。
- 集計 - 集計によって、各複製からの関数値をどのように組み合わせてシナリオの関数値を計算するかが決定されます。
最適化ジョブを実行するには、少なくとも1つのアクティブな目標が必要です。
[実行]タブ
[実行]タブは、1つの以上のジョブを実行する場所です。次のプロパティがあります。
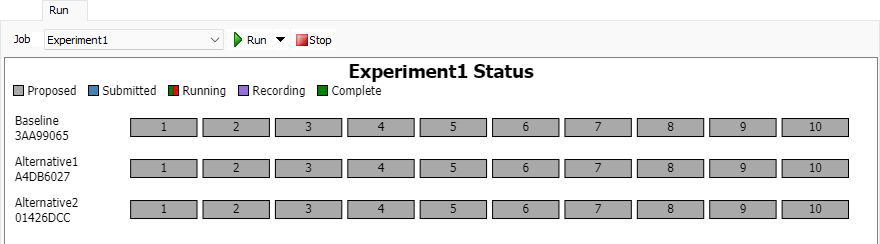
ジョブ
ジョブを選択します。これは、[実行]ボタンが押されたときに実行するジョブです。選択したジョブのタイプによって、このプロパティの下に表示されるプロパティも決定されます。
実行
選択されたジョブを実行します。
複数実行
実行する複数のジョブを選択可能なポップアップを開きます。複数のジョブを実行すると、ジョブはポップアップに表示された順序で順番に実行されます。
ジョブステータス
[ジョブステータス]グラフには、選択されたジョブのステータスが表示されます。選択されたジョブが実行中の場合は、ジョブの実行に合わせてグラフが更新されます。
最適化ジョブが選択された場合は、次のプロパティを使用できます。
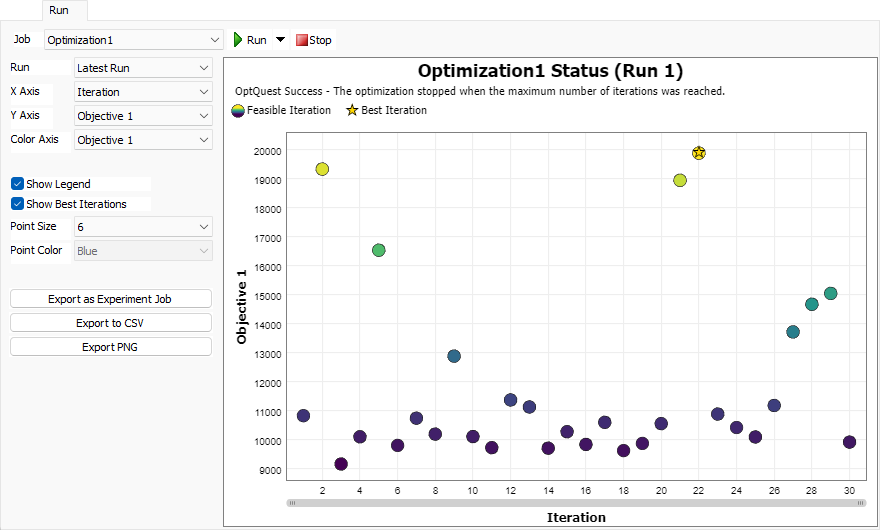
ジョブステータス
最適化の[ジョブステータス]グラフには、反復あたり1ポイントが散布図として表示されます。反復は、シナリオだけでなく、次のようなそのシナリオに関する追加情報も表します。
- 反復番号
- すべての目標値
- 反復ランク(ランク1が最適なシナリオ)
- 破られた制約(もしあれば)
実行
[ジョブステータス]グラフに表示する実行を選択します。
X軸
水平のX軸として使用する値を選択します。
Y軸
垂直のY軸として使用する値を選択します。
色軸
色軸の値を選択します。グラフ上の各ポイントの色は、色のグラデーションから選択されます。最も高い値は黄色を表し、最も低い値は濃い紫色を表します。
凡例を表示
このチェックボックスをオンにすると、[ジョブステータス]グラフ上に凡例が表示されます。
最適な反復を表示
このチェックボックスをオンにすると、最適な反復に金色の星印が付けられます。目標が1つの場合は、1つの反復だけがマークされます。目標が複数の場合は、トレードオフ曲線上の各反復がマークされます。
点のサイズ
[ジョブステータス]グラフ上の各シナリオを示す点のサイズを設定します。
点の色
色軸に対して[なし]を選択した場合は、このプロパティを使用して反復の色を指定できます。
実験ジョブとしてエクスポート
グラフ内の点をクリックすることによって、シナリオを選択できます。複数のシナリオが選択されている場合は、それらのシナリオを定義する実験ジョブを作成できます。
CSVにエクスポート
[ジョブステータス]グラフの生成に使用されるデータを含むCSVファイルを保存します。
PNGのエクスポート
現在の[ジョブステータス]グラフを表示する画像ファイルを保存します。
[詳細]タブ
[詳細]タブを使用すると、すべてのジョブに適用される追加の設定を構成することができます。次のプロパティがあります。
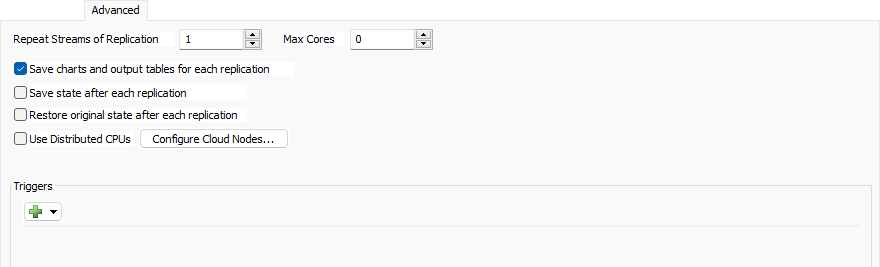
複製のストリームを繰り返す
複製を指定して、同じ乱数ストリームを使用するモデルの手動実行(実験ツールの複製ではありません)を設定します。これを有効にするには、ランダムストリームを繰り返す必要があります。
コアの最大数
実験ツールで使用するコアの最大数を指定します。値0は、使用可能なすべてのコアの使用が必要なことを示します。分散CPUを使用している場合、このプロパティは無視されます。
複製ごとにグラフを保存し、表を出力
このチェックボックスをオンにすると、各複製の最後で、実験ツールがダッシュボード統計、統計コレクター、および計算済みテーブルに関するデータをモデルに保存するため、後で結果の一部として表示できます。
各複製後に状態を保存
このチェックボックスをオンにすると、各複製の完全なシミュレーション状態がモデル実行の最後で結果データベースファイルに保存されます。後で、データベースから状態ファイルを抽出して、すべての複製の最終状態を表示できます。
各複製後に元の状態に戻す
このチェックボックスをオンにすると、FlexSimによって各モデルの実行の間にモデルが完全に再ロードされます。リセットするたびにモデルがまったく同じ状態に正しくリセットされず、後続の複製結果に影響を与える「スピルオーバー」状態を望まない場合は、このチェックボックスをオンにします。ただし、ツリーを完全に再ロードするため、各複製を実行するのに時間がかかる可能性があります。
分散CPUを使用する
ローカルマシンのCPUではなく、ネットワークまたはインターネット経由で使用可能なCPUを使用する場合は、このチェックボックスをオンにします。このチェックボックスがオンになっている場合は、実験ツールが[グローバル設定]で指定されたマシンを使用しようとします。詳細については、「クラウドでのジョブの実行」を参照してください。
クラウドノードの設定...
このボタンをクリックすると、[グローバル設定]ウィンドウが開きます。このウィンドウでは、実験ツールで使用可能なクラウドノードのリストを編集できます。
トリガー
実験ツールは、各ジョブのさまざまな時刻にトリガーを起動します。各トリガーの説明を以下に示します。
| 名前 | タイミング |
|---|---|
| On Start Of Job | ユーザーが[実行]ボタンをクリックした直後に起動されます。 |
| On Start Of Replication | モデルが実行を開始する直前の子プロセスで起動されます。 |
| On End Of Warmup | ウォームアップ時間に子プロセスで起動されます。 |
| On End Of Replication | 実行が終了したときに子プロセスで起動されます。結果が子プロセスから返されたときにメインのプロセスで起動されます。param(3)が存在する場合は、トリガーが親プロセスで起動されます。そうでない場合は、子プロセスで起動されます。 |
| On End Of Job | ジョブが終了したときに起動されます。 |