強化学習のトレーニング
トレーニングの概要
強化学習アルゴリズムのトレーニングをはじめる前に、強化学習に関する主要な概念を必ず復習してください。トレーニングの準備の一環として、ここまでに付属のPythonスクリプトをダウンロードし、それらのスクリプトを実行する環境を構成しているはずです。次に、FlexSimモデルをエージェントが学習する環境として使用し、強化学習アルゴリズムをトレーニングする方法の例として、それらのスクリプトを変更して使用します。
FlexSimモデルの準備
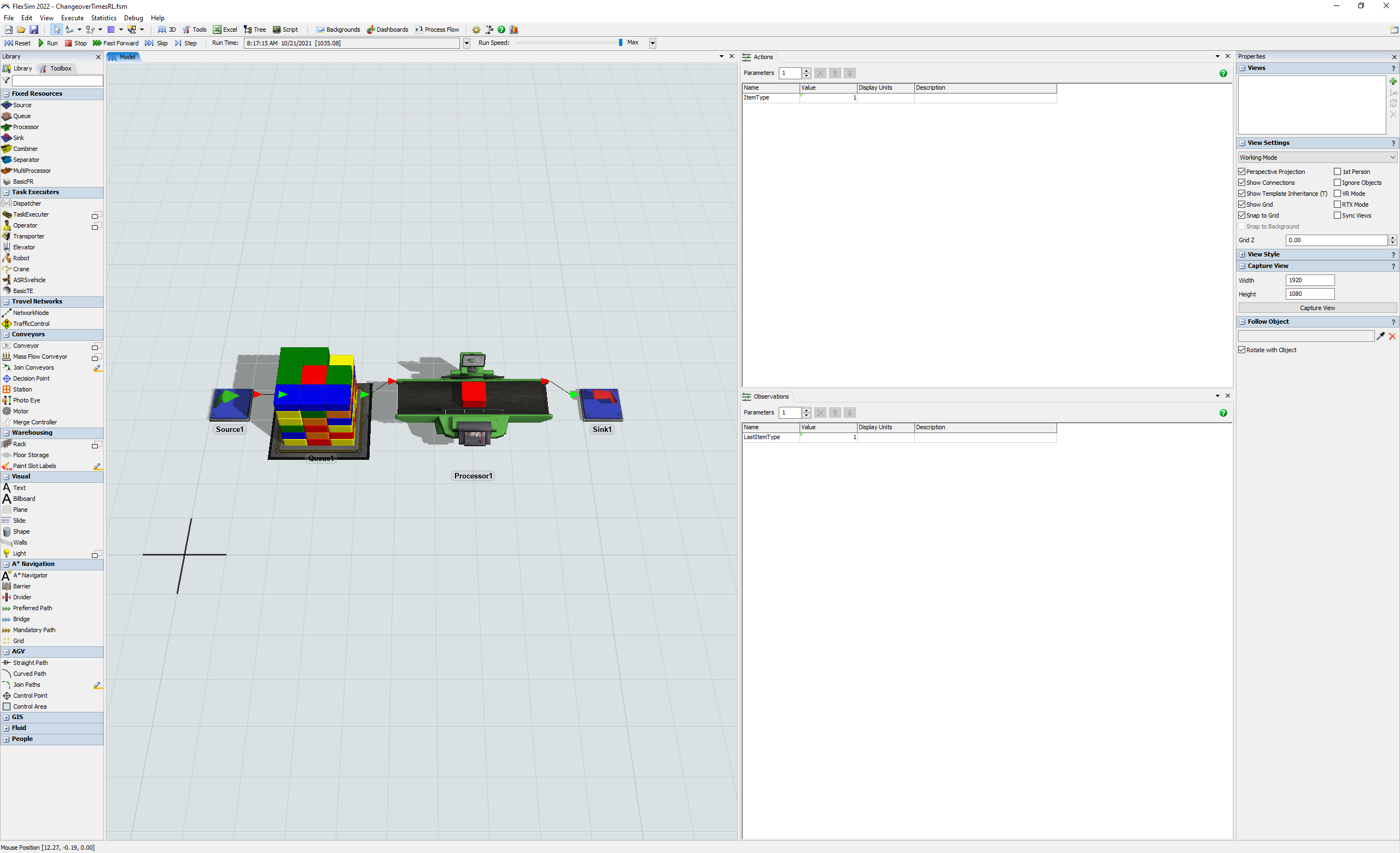
スクリプトを実行してトレーニングを開始する前に、強化学習アルゴリズムのトレーニングに関係する関数に応答できるようFlexSimモデルを構成する必要があります。この例では、シミュレーションモデル自体ではなく強化学習に集中できるよう、シンプルなサンプルモデルを構築します。
このモデルには、1から5までのランダムなアイテムタイプが到着します。これらのアイテムをプロセッサで処理します。設定時間はアイテムタイプを変えるごとに変化します。スループットを最大化するため、次にどのアイテムを処理するかを選択するよう、アルゴリズムをトレーニングします。次にどのアイテムをプルするかを決めるルールを明示的にプログラムする代わりに、交代時間を最小化するようアルゴリズムに学習させます。
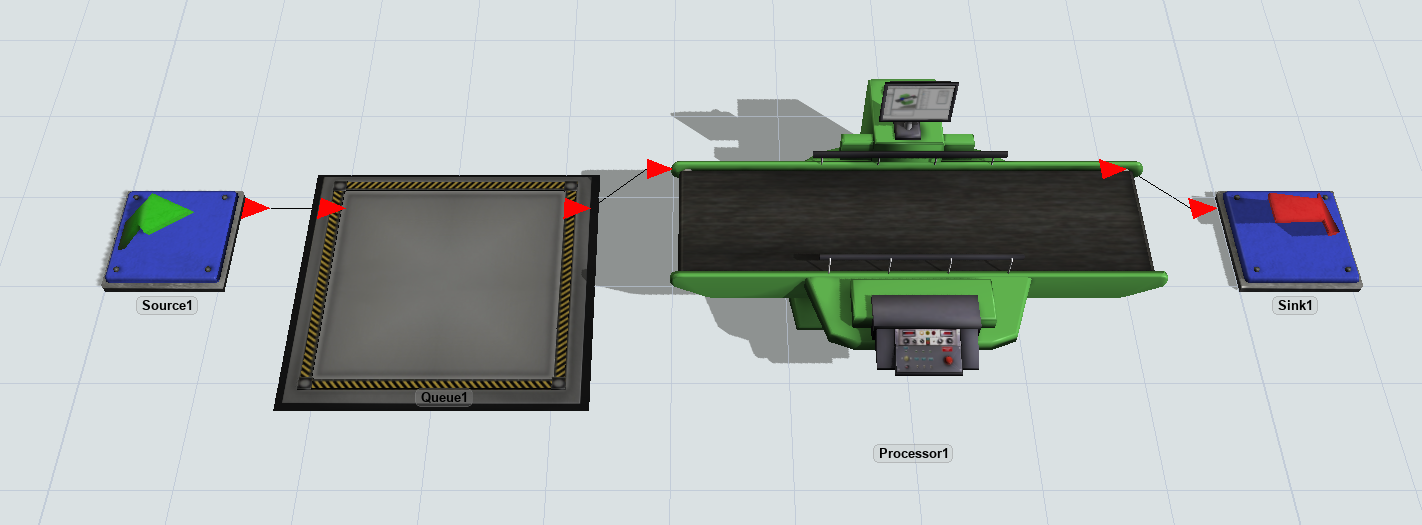
ステップ1 シンプルモデルの作成
- ソース、キュー、プロセッサ、シンクを新しいモデルにドラッグします。
- 次に示すようにオブジェクトを接続します。
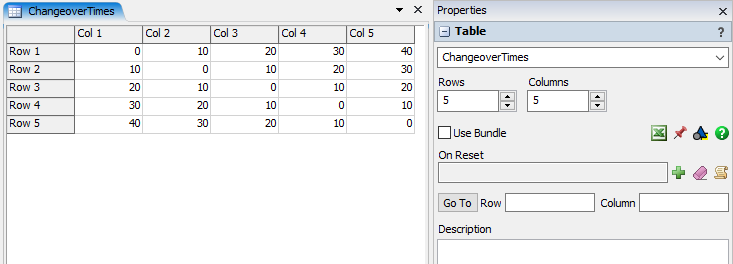
- [ツールボックス]ペインに[グローバルテーブル]を追加します。
- グローバルテーブルの[プロパティ]ペインで、名前を[ChangeoverTimes]に変更し、行と列の数を5に設定します。
- 次のデータをテーブルに入力します。各セルは、それぞれのアイテムタイプを処理するため必要な設定時間の長さを表します。たとえば、アイテムタイプ1から4に変更するには30秒の設定時間が必要です。
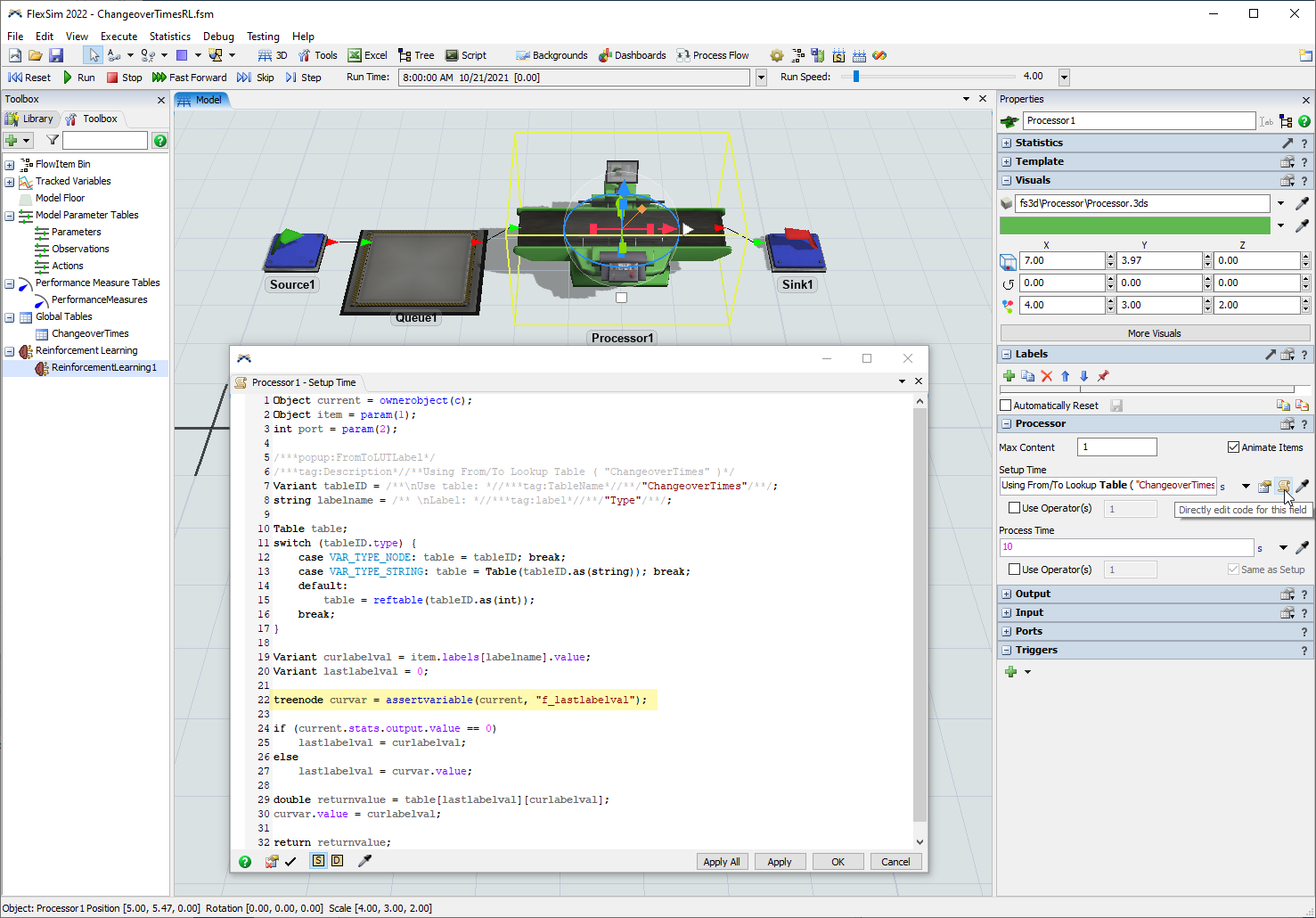
- プロセッサをクリックして、[プロパティ]を編集します。
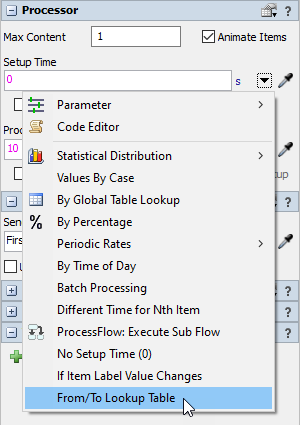
- [設定時間]フィールドで、ドロップダウンの[ルックアップテーブル元/先]を選択します。
- [テーブル]の[ChangeoverTimes]を選択し、[ラベル]は"Type"のままにします。
- ソースをクリックして、[プロパティ]を編集します。
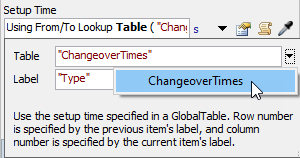
- [On Creation]トリガーを追加し、[データ]>[ラベルと色を設定]を選択します。
- [値]を
duniform(1,5,getstream(current))に変更します。 - モデルを[ChangeoverTimesRL.fsm]という名前で[保存]します。
- モデルを[リセット]して[実行]します。アイテムタイプを変更するとき、プロセッサに設定時間が含まれていることを確認してください。
ステップ2 アクションと観察パラメータの準備
- [ツールボックス]ペインで、[統計]>[モデルパラメータテーブル]を追加します。
- 新しいParameters1テーブルを右クリックし、[名前を変更]を選択します。
- テーブルの新しい名前として、「Observations」と入力します。
- [ツールボックス]ペインで、[統計]>[モデルパラメータテーブル]をもう1つ追加します。
- 新しいParameters1テーブルを右クリックし、[名前を変更]を選択します。
- テーブルの新しい名前として、「アクション」と入力します。
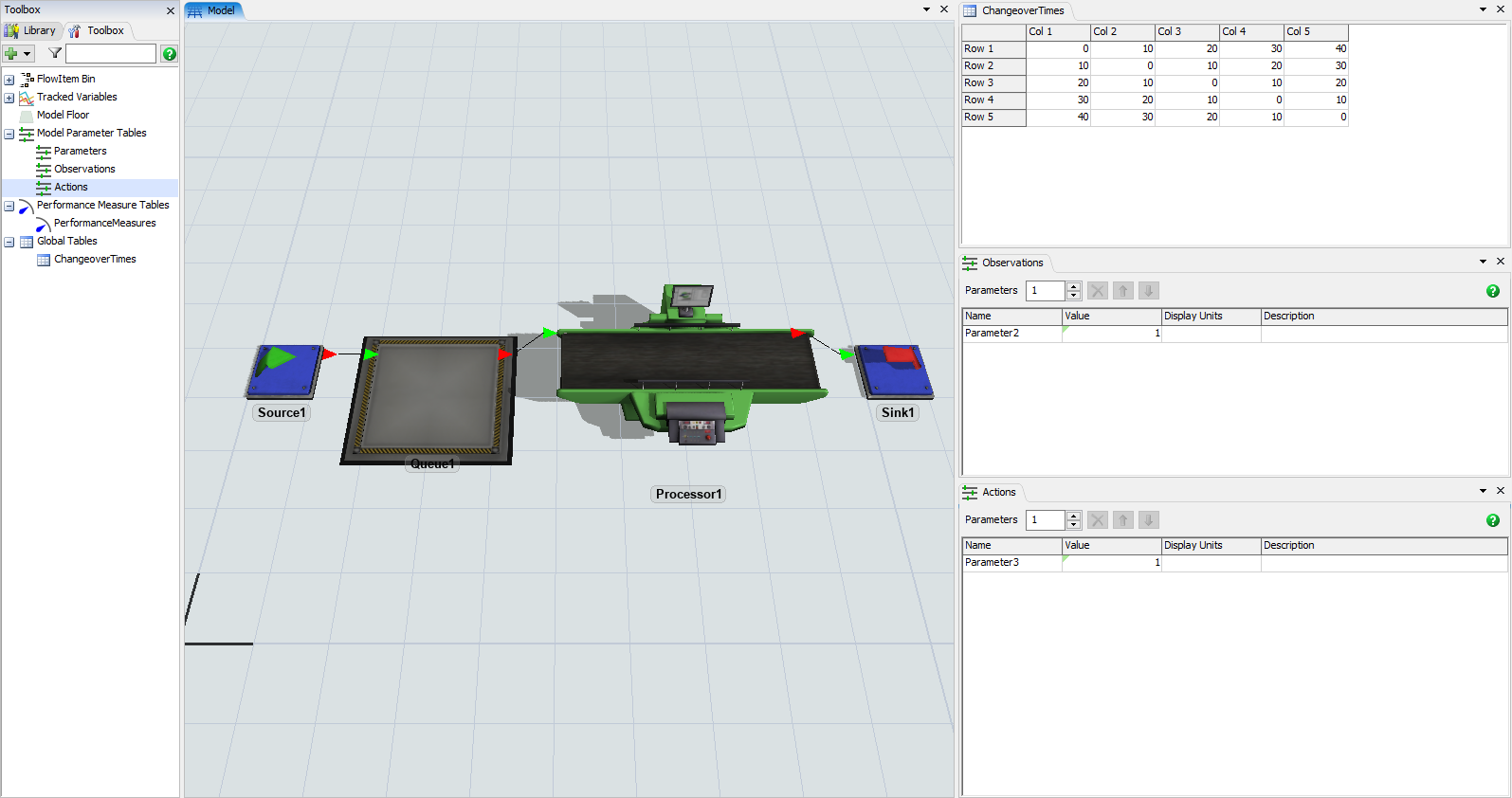
- [Observations]テーブルビューで、[Parameter2]を[LastItemType]に変更します。
- [Observations]テーブルビューで、値[1]が表示されているセルをクリックします。
- ドロップダウンボタンをクリックしてポップアップを開き、そのパラメータのプロパティを変更します。
- [タイプ]を[整数]に、[上限]を[5]に変更します。
- [Observations]テーブルビューの空白部分をクリックして適用し、ポップアップを閉じます。
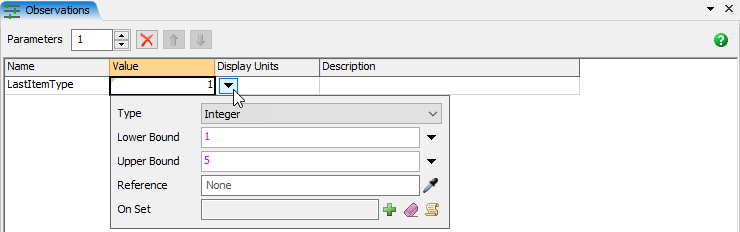
- [アクション]テーブルビューで、[Parameter3]を[ItemType]に変更します。
- [アクション]テーブルビューで、値[1]が表示されているセルをクリックします。
- ドロップダウンボタンをクリックしてポップアップを開き、そのパラメータのプロパティを変更します。
- [タイプ]を[整数]に、[上限]を[5]に変更します。
- [アクション]テーブルビューの空白部分をクリックして適用し、ポップアップを閉じます。
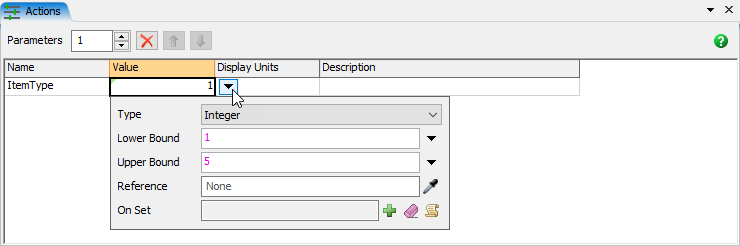
- プロセッサをクリックします。[プロパティ]ペインで[入力]パネルを展開し、[プル]チェックボックスをオンにします。
- [プル方法]ドロップダウンで、[ベストアイテムからプル]オプションを選択します。
- [ラベル]ドロップダウンを[カスタム値]に変更し、[式]として次のコードスニペットを入力します。
- モデルを[保存]します。
- モデルを[リセット]して[実行]します。赤のアイテム(タイプ1)が存在すれば、プロセッサによってプルされることを確認します。
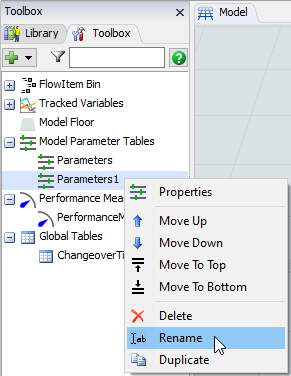
item.Type == Model.parameters["ItemType"].value
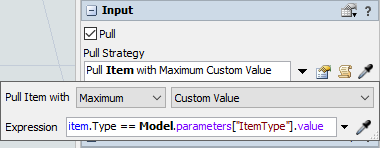
これによりプロセッサは、ItemTypeパラメータが存在すれば、そのパラメータと一致するアイテムをプルします。パラメータがない場合、最も古いアイテムをプルします。
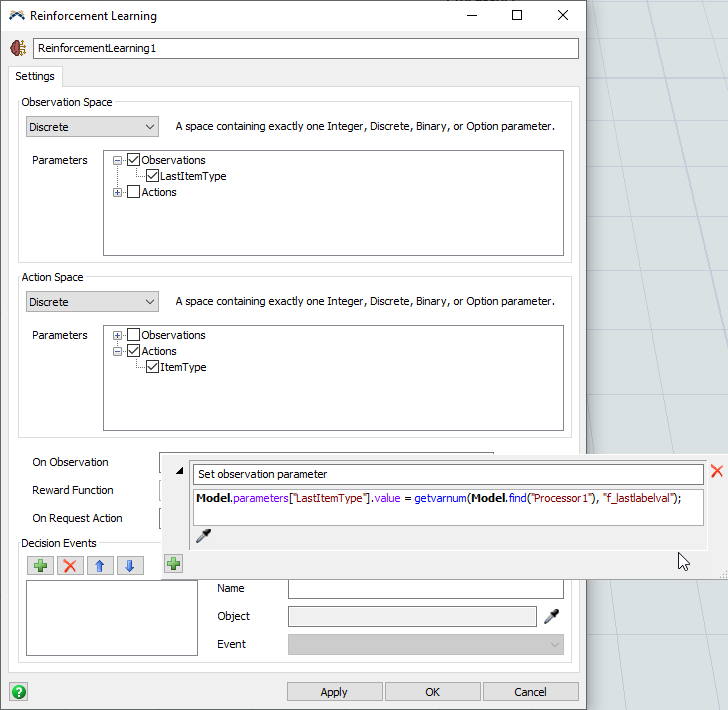
ステップ3 強化学習の構成
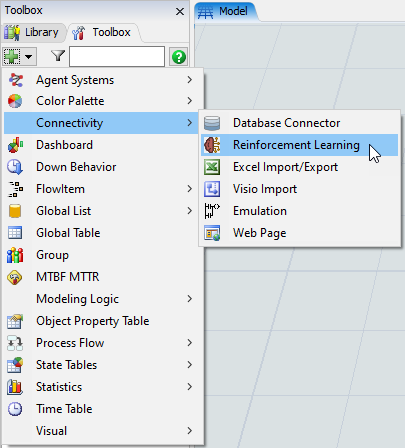
- [ツールボックス]ペインで、[接続性]>[強化学習]ツールを追加します。
- [監視スペース]グループで、ドロップダウンメニューの[離散]を選択します。
- [パラメータ]で[Observations]を展開し、[LastItemType]チェックボックスをオンにします。
- [アクションスペース]グループで、ドロップダウンメニューの[離散]を選択します。
- [パラメータ]で[アクション]を展開し、[ItemType]チェックボックスをオンにします。
- [適用]ボタンをクリックして、変更を保存します。
- プロセッサをクリックし、[設定時間]ピックリストで[コード]ボタンを押すと、コードにより
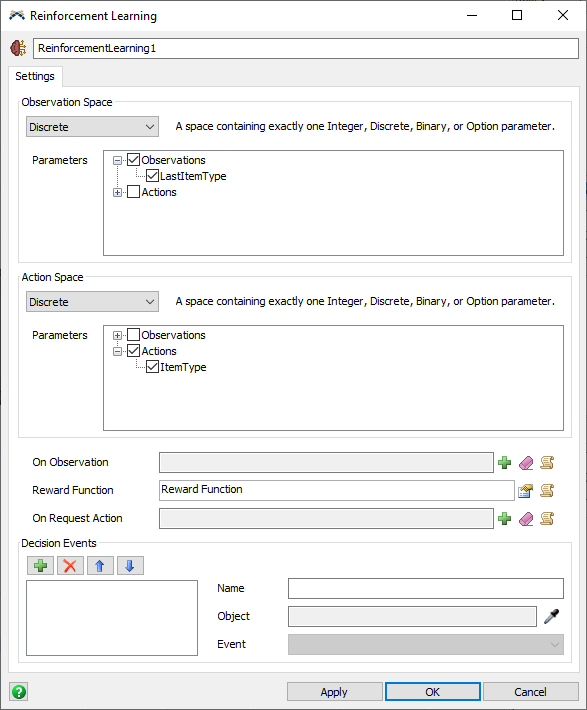
"f_lastlabelval"という変数が設定されます。この変数を使用して、強化学習ツールのOn Observationコールバック内からLastItemType観察パラメータを設定します。 - [強化学習]のプロパティウィンドウで、[On Observation]トリガーの横の[追加]ボタンを推し、[コードスニペット]を選択します。
- 説明テキストを[コードスニペット]から[観察パラメータの設定]に変更します。
- 次のコードスニペットをフィールドに入力または貼り付けします。
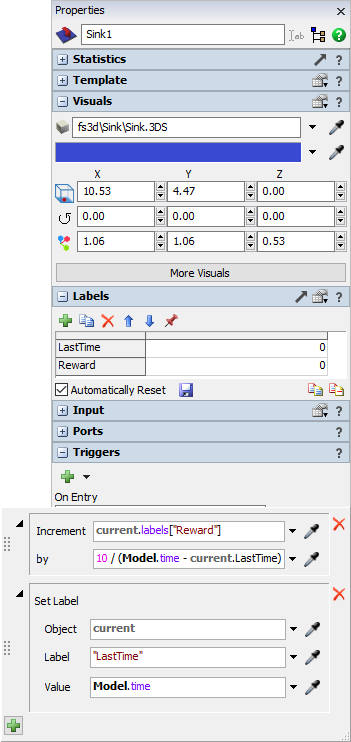
- [報酬機能]に入力する前に、アイテムがモデルを離れるときにシンクがラベル上の報酬額を集めるように構成します。
- 3Dビューでシンクをクリックします。[ラベル]ペインで数値ラベルを追加し、[LastTime]という名前を付けます。
- もう1つ数値ラベルを追加し、[報酬]という名前を付けます。
- [自動リセット]ボタンをチェックし、保存アイコンを押して、ラベルのリセット値に0を保存します。
- [トリガー]パネルで、[On Entry]トリガーを追加します。
- トリガーに[データ]>[増分値]オプションを追加します。
- [増加]ドロップダウンで、「
current.labels["Reward"]」を選択または入力します。 - [増分]フィールドに、「
10 / (Model.time - current.LastTime)」と入力します。 - トリガーに[データ]>[ラベルを設定]オプションを追加します。
- [オブジェクト]を[現在]に、[ラベル]を"LastTime"に変更します。
- [値]に「
Model.time」と入力します。 - [強化学習]のプロパティウィンドウに戻って、[報酬機能]のパラメータを編集します。
- [報酬機能]の説明テキストを[スループットに基づいた報酬]に変更します。
- 次のコードスニペットをフィールドに入力または貼り付けします。
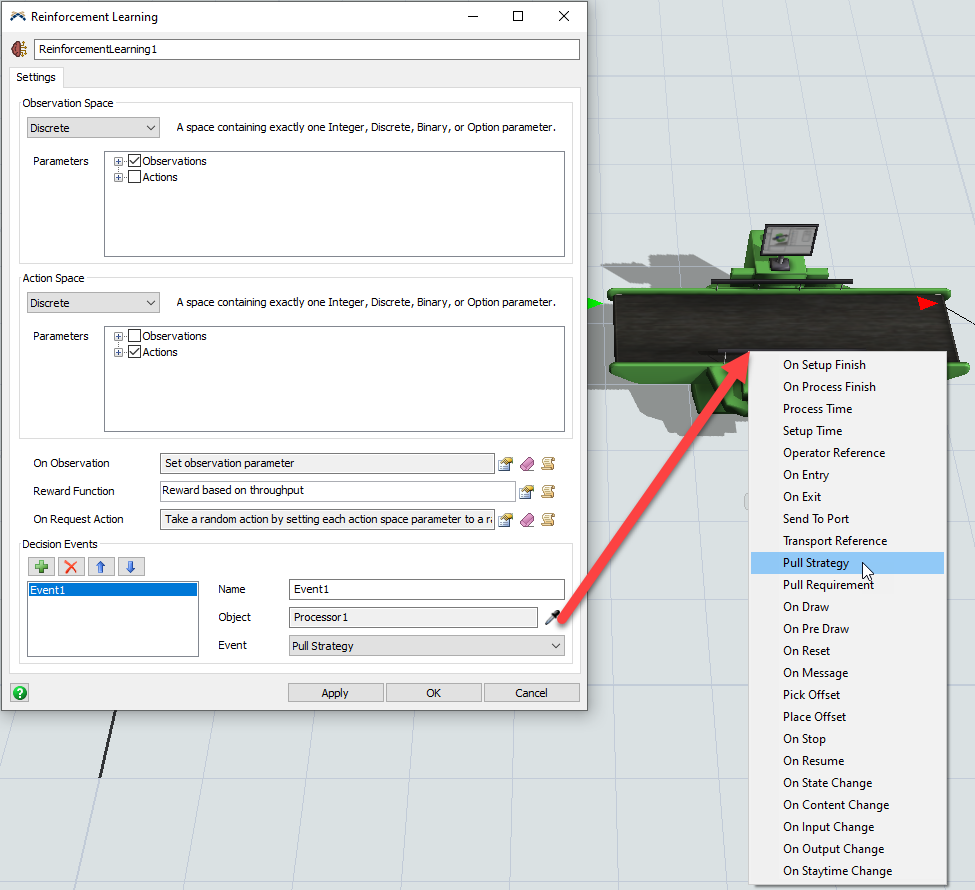
- [On Request Action]トリガーに、[ランダムなアクション]のオプションを追加します。
- [決定イベント]グループで、新しいイベント参照を追加し、プロセッサの[Pull Strategy]イベントをサンプルします。
- [OK]ボタンをクリックして変更を適用し、ウィンドウを閉じます。
- モデルを[保存]します。
- モデルを[リセット]して[実行]します。プロセッサが、毎回のプルの前にランダムに変化するItemTypeパラメータに基づいて、ランダムなアイテムをプルするようになったことを確認します。キューに要求されたアイテムタイプが存在しない場合、プロセッサはキューの最初のアイテムをプルします。
Model.parameters["LastItemType"].value = getvarnum(Model.find("Processor1"), "f_lastlabelval");
これにより、速く処理されるアイテムには大きな報酬が、交代時間の長いアイテムには小さな報酬が与えられます。
double reward = Model.find("Sink1").Reward;
Model.find("Sink1").Reward = 0;
int done = (Model.time > 1000);
return [reward, done];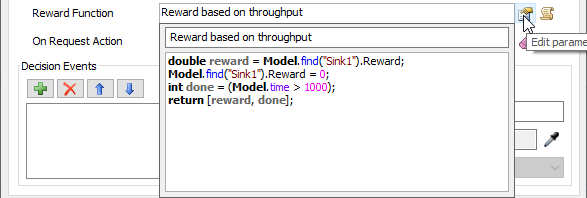
これにより、最後の観察以後にモデルを離れた各アイテムについて報酬が与えられるようになります。また、モデルが最低1,000秒間実行されるとトレーニングエピソードが完了することも指定されます。
On Request Actionトリガーは、モデルがトレーニングモードではなく通常に実行されるとき起動されます。ここでは、モデルが通常に実行されるときランダムなアクションを行うようにしておきます。
環境接続のテスト
ここで、Pythonスクリプトに戻ってトレーニングを開始します。「強化学習に関する主要な概念」を必ず復習し、付属のPythonスクリプトをダウンロードして、それらのスクリプトを実行する開発環境を構成したことを確認してください。
flexsim_env.pyスクリプトにはFlexSimEnvクラスの定義が含まれており、PythonからFlexSimへの通信に使用できます。このクラスには、モデルとともにFlexSimを起動し、ソケットを使用してモデルと通信するための関数が含まれています。
flexsim_env.pyファイルのmain()関数は、PythonからFlexSimへの接続をテストするために使用できるよう定義されています。
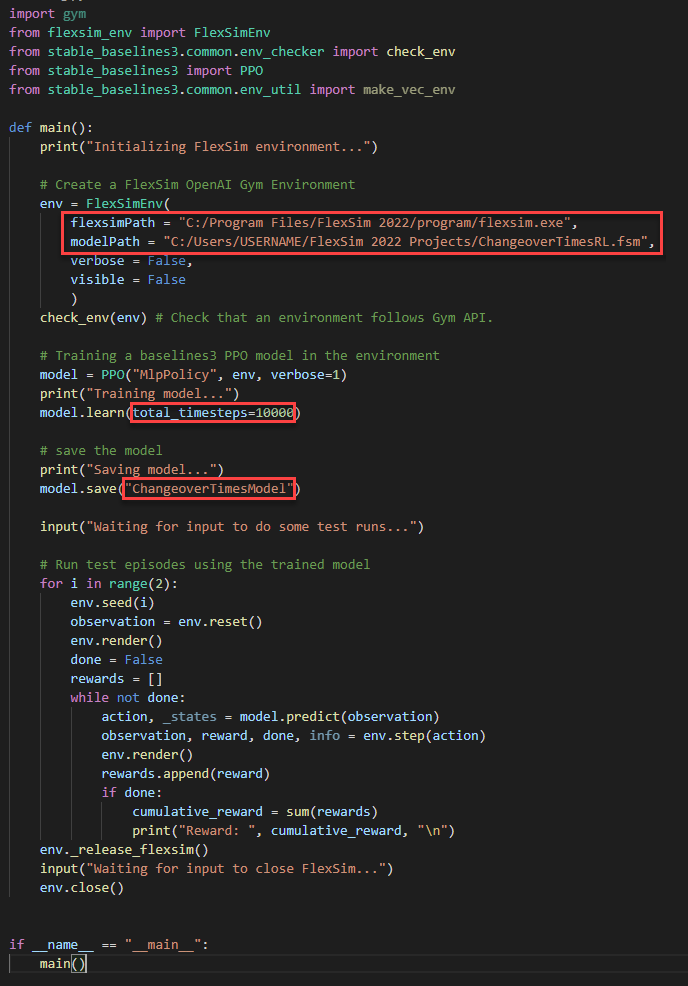
- flexsim_env.pyスクリプトの末尾近くで、flexsimPathとmodelPathを、それぞれFlexSimがインストールされている場所と、モデルが保存されている場所を参照するよう変更します。例を示します。
- 上端の[Pythonファイルの実行]ボタンを押して、flexsim_env.pyスクリプトを実行します。
- Pythonターミナルのウィンドウでいずれかのキーを押し、FlexSimを閉じてPython処理を終了します。
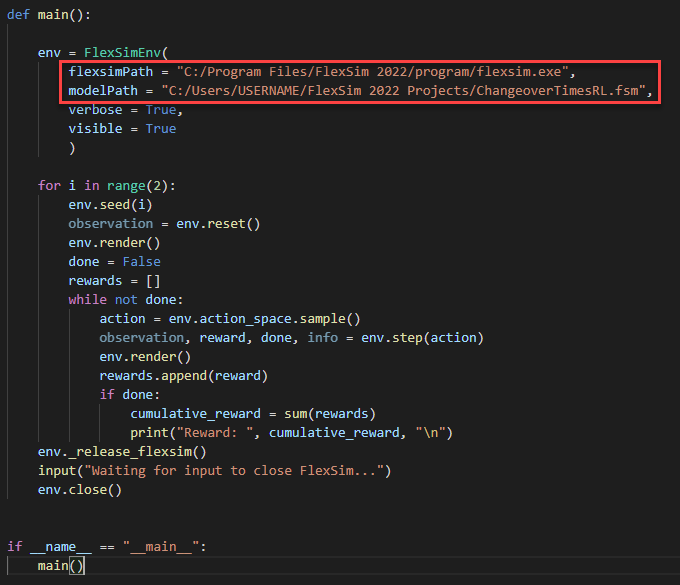
パスのなかでは必ずスラッシュ「/」を使用してください。バックスラッシュ「\」は使用できません。バックスラッシュ文字は、Python文字列内では特別なエスケープ文字です。
すべてが正しく構成されていれば、スクリプトによってFlexSimの新しいインスタンスが起動され、モデルが開きます。Pythonターミナルのウィンドウには、動作の各ステップを説明するステートメントが表示されます。
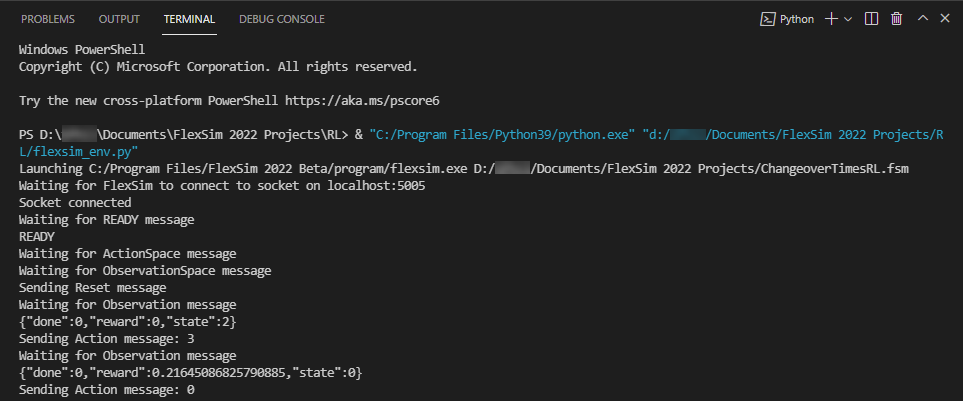
パッケージの依存関係が欠けている、またはAccess Deniedアクセス許可の問題に関するエラーが発生した場合、Python環境の設定を調整して問題を解決する必要があります。_launch_flexsim(self)関数はPython関数subprocess.Popen(args)を呼び出し、これは実行に管理アクセス許可が必要な可能性があります。
この環境にはverboseとvisibleの2つの追加パラメータがあり、スクリプトがPython出力に表示を行うか、およびFlexSimを可視ウィンドウとして表示するかを決定します。
また、この環境にはFlexSimへのソケット接続をコントロールするaddressとportの2つのパラメータもあります。デフォルトでは、ポート5005の「localhost」を使用しますが、FlexSimEnvクラスのインスタンスを作成するときにこれらの値をオーバーライドできます。
アルゴリズムのトレーニング
flexsim_env.pyスクリプトがFlexSimを正しく起動し、モデルのテストエピソードを実行できれば、強化学習アルゴリズムのトレーニングの準備が整いました。
flexsim_training.pyスクリプトには、FlexSimEnvを使用してStable Baselines3 PPOアルゴリズムをトレーニングするサンプル関数が含まれています。
- flexsim_training.pyスクリプトで、flexsimPathとmodelPathを、それぞれFlexSimがインストールされている場所と、モデルが保存されている場所を参照するよう変更します。
- 上端の[Pythonファイルの実行]ボタンを押して、flexsim_training.pyスクリプトを実行します。
- パッケージが存在しないエラーを修正するには、Pythonターミナルのウィンドウを使用して、欠けているパッケージをインストールします。たとえば、「pip install stable-baselines3」コマンドを入力してstable-baselines3パッケージをインストールします。
- 必要なパッケージがインストールされたら、[Pythonファイルの実行]ボタンを押して、flexsim_training.pyを再実行します。
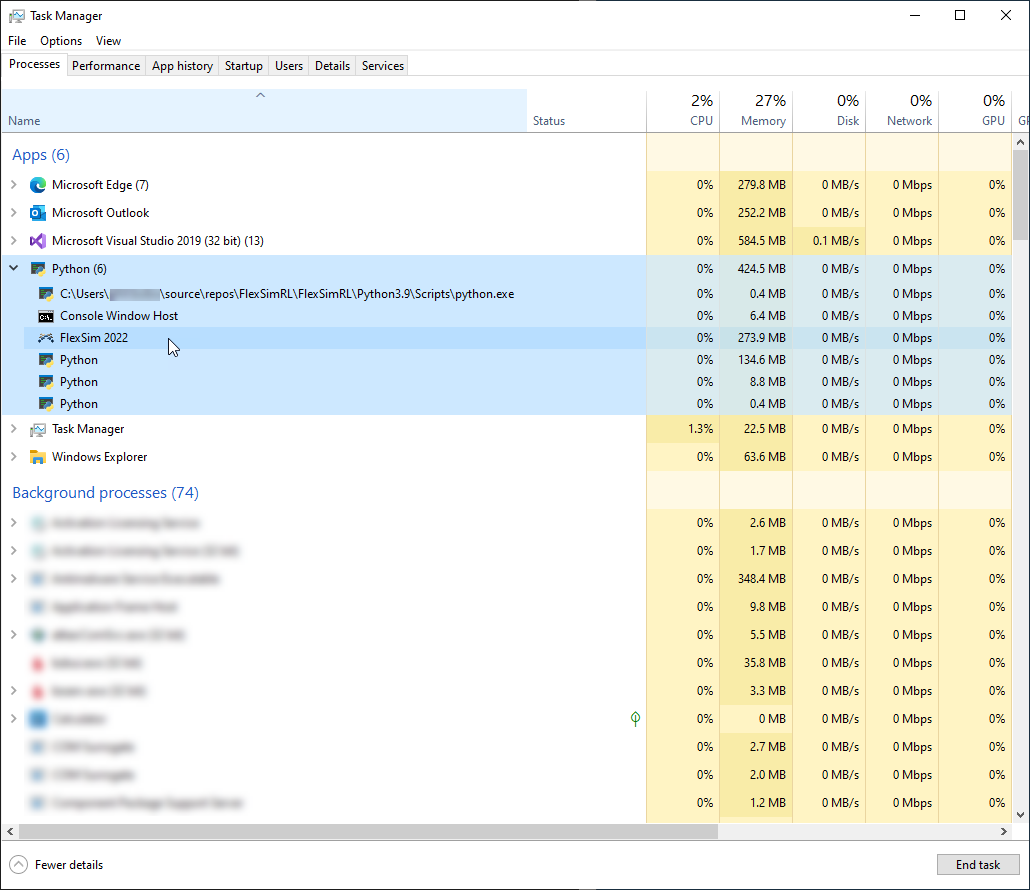
- このスクリプトではFlexSimEnvのvisibleがFalseに設定されているため、FlexSimウィンドウは表示されません。その代わりにタスクマネージャーを使用して、FlexSimプロセスがバックグラウンドプロセスとして作成されたことを確認できます。このプロセスは、Pythonプロセスの下に表示されることがあります。
- アルゴリズムが学習するにつれ、Stable Baslines3はトレーニングのステータスについての情報をPythonウィンドウに表示します。
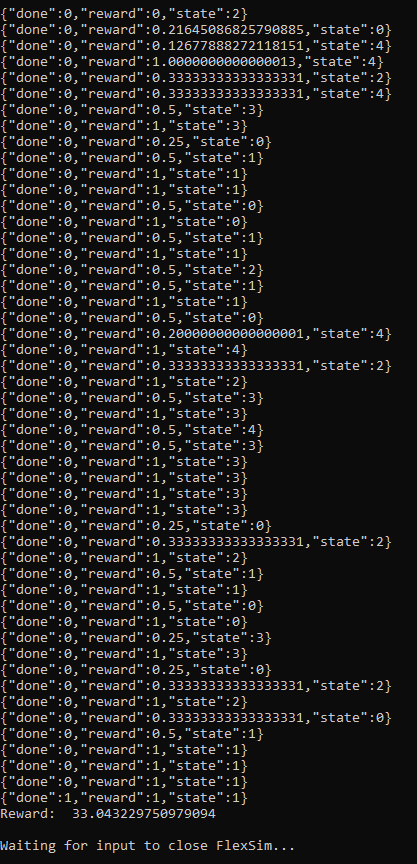
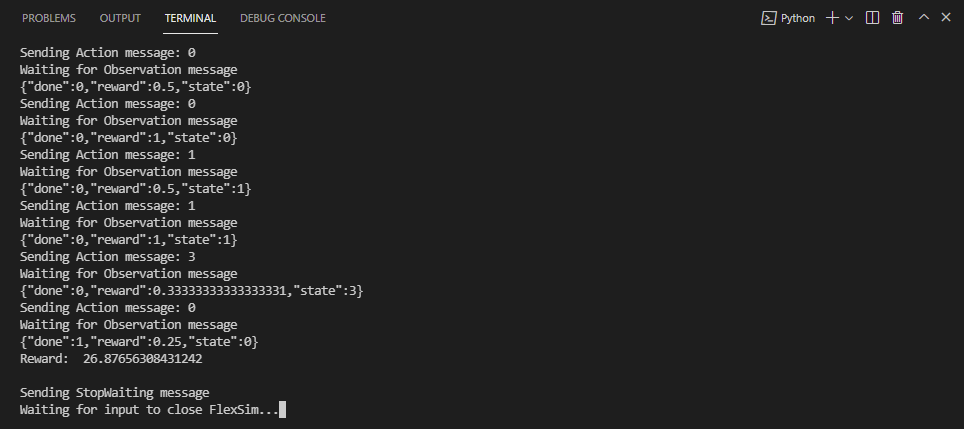
- モデルの保存後に、スクリプトはキーが押されるまで待ってから、トレーニング済みモデルを使用していくつかのテストエピソードを実行します。以下の出力では、エージェントは多くの場合にステップごとに報酬1を受け取っていることが分かります。これは、例のモデルで交代時間が発生していないことを示します。
- Windowsエクスプローラを開いてPythenプロジェクトのディレクトリを調べると、トレーニング済みAIモデルのデータを含むzipファイルが見つかります。このデータの使用法の詳細については、「学習済みモデルの使用」に進んでください。
トレーニング済みのモデルを保存するファイルの名前を「ChangeoverTimesModel」に変更します。
また、model.learn()関数に渡されるtotal_timestepsを変更することで、アルゴリズムをどれだけの時間トレーニングするかを変更できることにも注目してください。
おそらく、パッケージが存在しないため、「"stable_baselines3"という名前のモジュールがありません」などのエラーが出力されます。
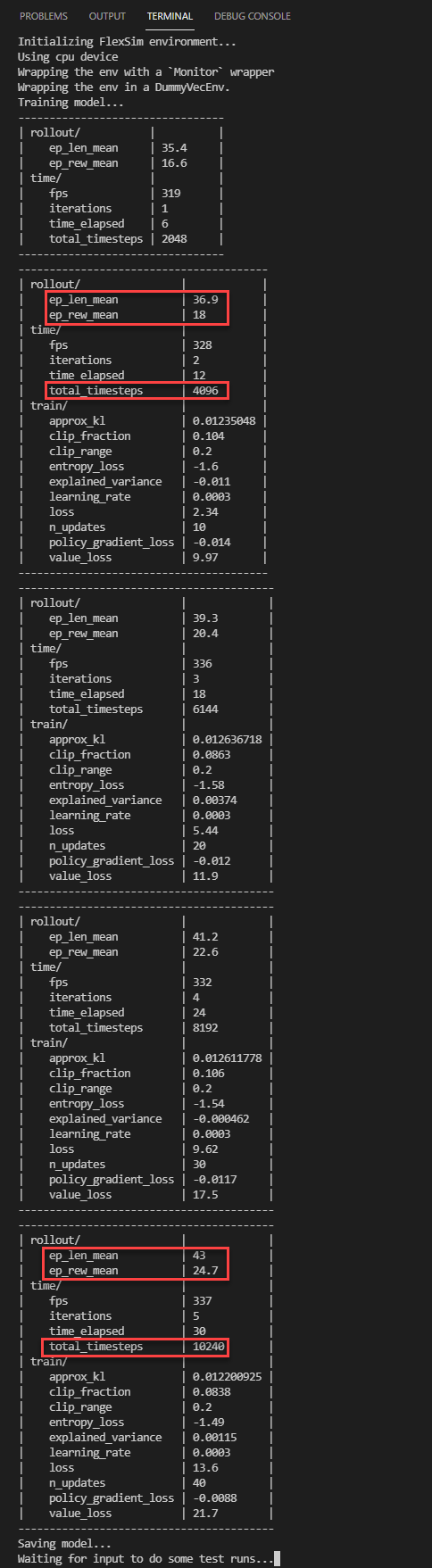
タイムステップが増えるにつれ、エピソードの平均時間(ep_len_mean)が長くなるため、上のステータスが表示されます。このシミュレーションモデルでは、決定ごとに1つのボックスを処理し、一定時間だけ実行するため、エピソードの長さはシミュレーションの合計スループットを表します。
エピソードあたりの平均報酬(ep_rew_mean)が増加していることも確認できます。この例で、これは同じ時間内により多くのアイテムが処理されていることを意味し、アルゴリズムが交代時間を最小化するような方法でアイテムをプルすることを学習して、システムの効率が向上していることが示唆されます。
このシンプルな例では、次にどのアイテムを処理するかを判断するとき、最後に処理されたアイテムのみを観察します。システムについてより多くのデータ、たとえばキュー内で利用可能なアイテムの情報などを観察することで、アルゴリズムをさらに改良できます。報酬機能を調整した場合も、アルゴリズムがどれだけ的確に学習を行うかが変化する可能性があります。このシンプルな例を拡張し、実験によって強化学習についてさらに深く学ぶことができます。