SQLクエリ
概要と主要な概念
FlexSimには、SQL言語を使用してモデル内のデータのクエリ、フィルタリング、優先順位付けを行うためのフレキシブルな方法が用意されています。SQLクエリを使用すると、ユーザーはFlexSimの1つ以上のテーブルを検索して基準に一致するデータを検索したり、そのデータに優先順位を付けたりといった、SQLライクな標準タスクを実行できます。FlexScriptコードを使用して手動でテーブルデータをループして並べ替えるのではなく、Table.query()コマンドを使用して1つのSQLクエリを作成し、すべての作業を行うことができます。
たとえば、モデルに次のようなグローバルテーブルがあるとします。
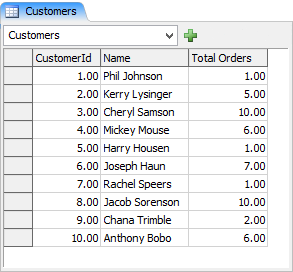
そのテーブルを検索して、最も発注量の多い顧客の名前とIDを探す場合、FlexScriptでは手動で次のような操作を行います。
Table customers = Table("Customers");
int bestRow = 0;
int highestTotalOrders = 0;
for (int i = 1; i <= customers.numRows; i++) {
int totalOrders = customers[i][3];
if (totalOrders > highestTotalOrders) {
bestRow = i;
highestTotalOrders = totalOrders;
}
}
int bestCustomerId = result[bestRow]["CustomerId"];
string bestCustomerName = result[bestRow]["Name"];
代わりに、SQLとFlexSimのTable.query()コマンドを使用すると、次のように簡単に行うことができます。
Table result = Table.query("SELECT CustomerId, Name FROM Customers \
ORDER BY [Total Orders] DESC LIMIT 1");
int bestCustomerId = result[1]["CustomerId"];
string bestCustomerName = result[1]["Name"];
これは非常にシンプルな例です。複数の結果の並べ替えや複数のテーブルの検索といったより複雑な作業は、FlexScriptで手動で実行するとさらに複雑になりますが、これらの複雑な検索もSQLのルールとSQLクエリの作成方法を理解すると、SQLを使用して比較的容易に行うことができます。
FlexSimのSQL機能には高度なクエリ技術も含まれています。これらのクエリ技術によって、標準テーブルのように構造化されていないモデル内のデータを検索できます。フローアイテム、タスクシーケンス、リソース、モデル内のあらゆるデータを検索し、概念化できるものをリストにできます。
例
次のセクションでは、SQLクエリに関連する主な概念を詳しく説明します。
最初のSQLクエリ
FlexSimでは、SQLクエリはTable.query()メソッドを使用して実行されます。
static Table Table.query(str queryStr[, ...])
ほとんどの場合、Table.query()コマンドは1つのテーブルの検索に使用します。次の例のグローバルテーブルをご覧ください。
5件以上の発注を行った顧客を検索し、アルファベット順に並べ替えるとします。これを行うには、次のコマンドを使用します。
Table result = Table.query("SELECT * FROM Customers \
WHERE [Total Orders] > 5 \
ORDER BY Name ASC");
SELECTステートメントは、クエリ結果にどの列をプルするかをクエリに指示します。SELECT *を使用すると、ソーステーブルのすべての列をクエリ結果に入れるようにクエリに指示します。また、SELECT CustomerId, Nameを使用する場合は、CustomerId列とName列のみをクエリ結果に入れます。FROMステートメントは、照会されるテーブルを定義します。ほとんどの場合、これは1つのテーブルのみですが、結合オペレーションに影響を与える複数のカンマ区切りテーブルである場合があります。結合オペレーションについては後半で説明します。ここではFROM Customersを定義します。これにより、SQLパーサーはモデル内のCustomersというグローバルテーブルを検索します。WHEREステートメントは、テーブルのエントリを一致させるフィルターを定義します。WHERE [Total Orders] > 5という式は、合計注文列の値が5より大きい行のみを求めていることを示します。WHEREステートメントでは、+、-、*、/などの数学演算子と、==、!=(および<>)、<、<=、>、>=、AND、ORなどの論理演算子を使用して式を定義できます。[ ]構文は、列名をスペースで区切って定義できるSQLデリミターです。Total Ordersの代わりにTotalOrdersという列を指定した場合は、[Total Orders]ではなく、クエリの列名にTotalOrdersを追加するだけで済みます。ORDER BYステートメントは、結果の並べ替え方法を定義します。ここでは、Name列で並べ替えます。これはテキスト列であるため、アルファベット順に並べ替えられます。任意で、ASCまたはDESCを配置すると、昇順または降順に並べ替えるかどうかを定義できます。デフォルトは昇順です。複数のコンマ区切り式を指定して、並べ替えを定義することもできます。追加の式では、同順位があるときの表示順序を定義します。たとえば、ORDER BY [Total Orders] DESC, Name ASCという式では、最初に総注文数で降順に並べ替えられ、その後、同順位のエントリ(Cheryl SamsonとJacob Sorensonの両方とも合計が10件)が名前のアルファベット順に並べ替えられます。\エスケープ文字を使用すると、文字列内の行の最後に\を使用して、複数の行にまたがって引用符で囲まれた文字列を拡張できます。SQLクエリでは、クエリが長すぎるため引用符付き文字列が1行に収まらないことがよくあります。また、インデント付きの複数の行を使用すれば、クエリがより読みやすくなります。- この例では使用されていませんが、
LIMITステートメントはクエリの最後に追加できます。これは一致の数を制限します。最良の3つの一致だけを求めている場合は、クエリの末尾にLIMIT 3を追加します。
クエリからのデータの取得
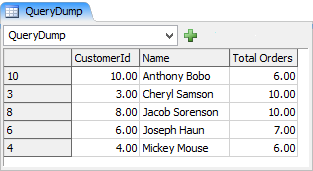
これでクエリが完了しました。結果は、テーブルの読み取り専用メモリ内インスタンスに保存されます。結果全体をグローバルテーブルやツリー内のノード上のテーブルにコピーするには、Table.cloneTo()を使用します。これにより、クエリ結果がテーブルやバンドルノードにコピーされます。この例では、QueryDumpという名前のグローバルテーブルを作成し、そのテーブルに結果をコピーできます。
Table result = Table.query("SELECT * FROM Customers \
WHERE [Total Orders] > 5 \
ORDER BY Name ASC";
result.cloneTo(Table("QueryDump"));
上のクエリをグローバルのQueryDumpテーブルにダンプすると、次の結果が得られます。
テーブルの選択
SQL言語は、一連の入力テーブルから結果テーブルを生成します。上の例では、"SELECT * FROM Customers"を使用しました。FROMはパーサーに、グローバルテーブル内で「Customers」という名前のテーブルを検索し、そのテーブルを検索するように指示します。FlexSimでは、Fromステートメントを使用して以下のすべてのテーブルを使用できます。
- グローバルテーブル
- グローバルリスト
- グローバル統計コレクター
- グローバル計算テーブル
さらに、実験やオプティマイザーのデータを扱うテーブルがいくつかあります。以下のリストは、実験者データに属するテーブルの一覧と説明です。
- Experiment.Scenarios - このテーブルには、シナリオ番号の列と各実験変数の列があります。各行は、その行の特定のシナリオの構成を表します。このテーブルは実験データを読み取り、オプティマイザーの影響を受けません。
- Experiment.PerformanceMeasures - このテーブルには、シナリオ番号と複製番号の両方の列と、各パフォーマンス指標の追加の列があります。各行には、シナリオ番号と複製番号のすべてのパフォーマンス指標が表示されます。最適化を実行している場合、このテーブルには最適化の結果が表示されます。
- Experiment.MyStatisticsCollector - このテーブルは、すべてのシナリオと複製でMyStatisticsCollector(またはモデル内の任意の統計コレクター)のデータを連結し、シナリオ番号と複製に2つの列を追加した結果です。これにより、すべての複製とシナリオの統計コレクターのデータを1つのクエリで分析することが可能になります。
または、検索用のテーブルを明示的に定義することもできます。これを行うには、特別な'$'識別子をクエリに使用し、追加のパラメータをTable.query()コマンドに渡します。たとえば、上と同じクエリを定義する代わりに、customersテーブルを次のように明示的に定義できます。
Table.query("SELECT * FROM $1 \
WHERE [Total Orders] > 5 \
ORDER BY Name ASC",
current.labels["Customers"]));
「Customers」テーブルを使用する代わりに、テーブルを$1として定義しています。つまり、Table.query()コマンドの最初の追加パラメータとして渡すテーブルが、検索対象のテーブルです。$2は、コマンドの2番目の追加パラメータに渡されるテーブルになります。通常のツリーテーブルデータまたはバンドルデータのいずれかを持つテーブルを、追加パラメータとして渡すことができます。ただし、Table.query()の別の呼び出しの結果のような、メモリ内結果テーブルは使用できません。つまり、FlexSimが適切に処理するためには、テーブルはFlexSimのツリー内のノードに保存されている必要があります。
このテーブル指定方法の採用によって、グローバルテーブルの使用は必須ではなくなりました。たとえば、customersテーブルがグローバルテーブルではなくラベルにある場合でも、シンプルなクエリを実行できます。
Table.query("SELECT * FROM $1 \
WHERE [Total Orders] > 5 \
ORDER BY Name ASC",
current.labels["Customers"]));
また、FlexSimのSQLパーサーによって、この単一テーブルの検索シナリオのSQLが少しシンプルになります。SQLの標準ではSELECTとFROMのステートメントが必要ですが、FlexSimのSQLパーサーはそれほど難解ではありません。テーブルとしてパラメータを1つだけ渡すと、渡されたテーブルが検索対象であると自動的に認識されます。したがって、SELECTステートメントとFROMステートメントを省略できます。これらを省略すると、本質的にはSELECT * FROM $1というステートメントを使用したことと同じになります。
Table.query("WHERE [Total Orders] > 5 ORDER BY Name ASC", current.labels["Customers"]);
追加の結果分析方法
Table.cloneTo()はモデルを設定したり、さまざまなクエリをテストしたりするときに非常に便利ですが、テーブル/バンドル全体をデータでクローン化するのは簡単ではなく、テーブルを作成するためのメモリスペースとCPU時間が必要になります。代わりに、Tableクラスが提供するメソッドとプロパティを使用して、結果を直接処理することもできます。
Table result = Table.query("SELECT * FROM Customers \
WHERE [Total Orders] > 5 \
ORDER BY Name ASC");
result.cloneTo(Table("QueryDump"));
for (int i = 1; i <= result.numRows; i++) {
string name = result[i]["Name"];
...
}
結合
FlexSimのSQLパーサーを使用して、複数のテーブル間の関係を照会することもできます。Customersテーブルと追加のOrders Tableを使用して詳しく説明します。
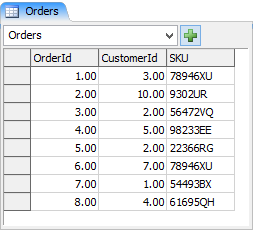
この例では、SKU 78946XUを注文した顧客に関連する情報を検索しようとしています。SKU 78946XUの各注文について、お客様の名前、CustomerId、OrderIdを知りたいとします。クエリは次のようになります。
Table result = Table.query("SELECT * FROM Customers, Orders \
WHERE \
SKU = '78946XU' \
AND Customers.CustomerId = Orders.CustomerId");
注意:
- ここでは、
FROM Customers, Ordersというステートメントを使用します。SQLでは、これを内部結合と呼びます。SQL Evaluatorは、Customersテーブルのすべての行とOrdersテーブルのすべての行を比較し、WHEREフィルターに一致する行と行のペアを確認します。 - ここで定義するフィルターは
WHERE SKU = '78946XU' AND Customers.CustomerId = Orders.CustomerIdです。目的は、SKU値 '78946XU' を持つOrdersテーブルの行を一致させることのみです。次に、SKUと一致した行について、Ordersテーブルで一致した行のCustomerIdに対応するCustomersテーブル内の行と一致させることです。 - SKUルールでは、これを
SKU = '78946XU'のみで実現できることに着目してください。SKUについて、OrdersテーブルがSKU列を持つ唯一のテーブルであるため、SQL Evaluatorは、SKU列がOrdersテーブルに関連付けられていることを自動的に認識します。Orders.SKUを使用してテーブルと列を明示的に定義することもできます。クエリをよりわかりやすくするために、これが望ましい場合もあります。ただし、これを使用しない場合でも、Evaluatorが自動的に関連を認識します。 - 一方、CustomerIdルールは、明示的に表と列を定義するために.(ドット)構文を使用します。これは、OrdersテーブルとCustomersテーブルの両方に「CustomerId」という名前の列があり、CustomersのCustomerId列とOrdersのCustomerId列を明示的に比較する必要があるためです。そこで、ドット構文を使用してテーブルと列を定義します。
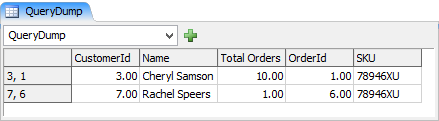
このクエリのresult.cloneTo(Table("QueryDump"))の結果は次のとおりです。
明示的に定義されたテーブル(ラベルなど)の場合は、次のようなクエリを使用します。
Table result = Table.query("SELECT * FROM $1 AS Customers, $2 AS Orders \
WHERE \
SKU = '78946XU' \
AND Customers.CustomerId = Orders.CustomerId",
current.labels["Customers"],
current.labels["Orders"]);
エイリアス
前述の例では、AS構造を使用してテーブルのエイリアスを作成しています。テーブルと列の両方の参照でエイリアスを作成できます。特に、$構文を使用している場合は、クエリの可読性が向上します。厳密には、テーブルエイリアスではAS修飾子は必要ありません。以下の両方が有効です。
SELECT * FROM $1 AS Customers, $2 AS Orders
SELECT * FROM $1 AS Customers, $2 AS Orders
エイリアスを定義したら、クエリの他の参照でテーブル名の代わりにそのエイリアスを使用します。
以下に、列エイリアスの定義例をいくつか示します。
SELECT Customers.CustomerId AS ID, Customers.Name AS Name
WHERE ID > 5 AND ID < 10
高度なクエリ手法
シミュレーションで生じる意思決定上の問題の中には、検索、フィルタリング、優先順位付けなどのSQLライクな構造の使用が役立つことが多々あります。ただし、シミュレーションは本質的に動的なシステムであるため、シミュレーションのデータ構造が、データベースの標準的な構造方法とは異なる場合があります。FlexSimの高度なSQLクエリ機能は、このギャップを埋めることを目的としており、モデラーがSQLの柔軟性と表現力を駆使し、モデルの状態を動的に照会します。
モデル内のさまざまな場所にキューイングするフローアイテムがある場合の例を見てみましょう。モデリングロジックが「最適な」フローアイテムを探そうとするケースが一般的ですが、最適なフローアイテムを見つけるには複雑なルールが必要な場合があります。場合によっては、各フローアイテムに一定の適格基準を割り当てることがあります。あるソースからフローアイテムの場所までの距離、フローアイテムがキュー内で待機していた時間、フローアイテムに割り当てられた優先順位などを考慮する場合もあります。これらのタイプの問題については、SQL言語の豊かな表現力を駆使して問題を比較的容易に解決できます。では、候補となるすべてのフローアイテムを準データベーステーブルとして表現し、SQLを使用してそのテーブル内のエントリを検索、フィルター、優先順位付けできたらどうでしょうか。
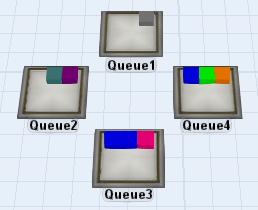
ここには4つのキューがあり、それぞれに一連のフローアイテムがあります。それぞれのフローアイテムに、そのフローアイテムのデータを定義するさまざまなラベルがあるとします。そのすべてのデータを表すフローアイテムのテーブルは、次のようになります。
| アイテム | 場所 | DistFromMe | 優先度 | ステップ | ItemType | Time Waiting |
|---|---|---|---|---|---|---|
| GrayBox | Queue1 | 9.85 | 3 | 5 | 6 | 5.4 |
| PurpleBox | Queue2 | 8.5 | 2 | 2 | 8 | 8.1 |
| TealBox | Queue2 | 8.5 | 8 | 12 | 5 | 7.2 |
| OrangeBox | Queue4 | 12.5 | 4 | 1 | 4 | 1.2 |
| GreenBox | Queue4 | 12.5 | 3 | 5 | 2 | 4 |
| BlueBox | Queue4 | 12.5 | 6 | 6 | 3 | 22.5 |
| PinkBox | Queue3 | 7.5 | 3 | 9 | 7 | 12.8 |
| BlueBox | Queue3 | 7.5 | 6 | 10 | 3 | 3.4 |
| BlueBox | Queue3 | 7.5 | 4 | 7 | 3 | 7.1 |
モデル構造をこれらの準テーブルの用語で表すことができれば、SQLを使用して複雑なフィルタリングやそれらのテーブルに基づく優先順位付けを行うことができます。
まずはシンプルなテーブルで試してみましょう。フローアイテムのQueue4の1つのキューのみを検索すると、アイテムの「ステップ」ラベルに格納されているステップ値だけが表示されます。ここでは、ステップ値が3より大きいフローアイテムを求めます。テーブルは、以下のようにさらにシンプルになります。
| アイテム | ステップ |
|---|---|
| OrangeBox | 1 |
| GreenBox | 5 |
| BlueBox | 6 |
コマンドは次のとおりです。
Table result = Table.query("SELECT $2 AS Item, $3 AS Step \
FROM $1 Queue \
WHERE Step > 3",
/*$1*/node("Queue4", model()),
/*$2*/$iter(1),
/*$3*/getlabel($iter(1), "Step"));
result.cloneTo()の結果は次のようになります。
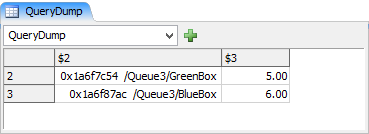
ここでは、2つの新しい概念を紹介します。1.オブジェクト参照をテーブルとして、2.個別の列の値をテーブルだけではなく$構文で定義します。
テーブルとしてのオブジェクト参照
クエリテーブルは次のように定義されています。
FROM $1 Queue
$1の参照は以下とバインドします。
node("Queue4", model())
実際のテーブルを参照するのではなく、モデル内のオブジェクトを参照します。これを行う際に、「仮想テーブル」の各行が、参照するオブジェクトのサブノード、つまりキュー内のフローアイテムに関連付けられます。そのため、テーブルの最初の行は、キュー内の最初のフローアイテム、2行目は2番目のフローアイテムに関連付けられます。
テーブル値としての$と$ iter()
selectステートメントは次のようになります。
SELECT $2 AS Item, $3 AS Step
$2を以下とバインドします。
getlabel($iter(1), "Step")
$3を以下とバインドします。
getlabel($iter(1), "Step")
Queue4の各フローアイテムとStepラベルに基づいて、検索している「仮想テーブル」は以下のようになります。
| アイテム | ステップ |
|---|---|
| OrangeBox | 1 |
| GreenBox | 5 |
| BlueBox | 6 |
$iter()コマンドを使用して、Queue4の内容をトラバースしてテーブルセルの値を判別します。 $iter() は対象テーブルの反復を返します。$iter(1)は$1の反復です。$1はQueue4であるため、$iter(1)はテーブルの特定の行、つまりQueue4のフローアイテムのサブノードの1つに関連付けられたQueue4の反復になります。
エバリュエーターがテーブル内の特定の行の値を取得する必要がある場合は、そのテーブル行に関連付けられたQueue4のフローアイテムのサブノードに$iter(1)を設定し、その式を再評価します。したがって、テーブルのGreenBox行(行2)にあり、その行のStep値を取得する必要がある場合は、$iter(1)をrank(Queue4, 2)に設定し、$3を評価します。$3は基本的にgetlabel(rank(Queue4, 2), "Step")を返します。その値は、テーブルセルの値として使用されます。
すべてのフローアイテムのテーブルの作成
ここまでで、1つのキューに対してクエリを実行できました。次は、すべてのキューを検索するようにクエリを拡張します。すべてのキューが上流にあるキューの出力ポートに接続されているとします。
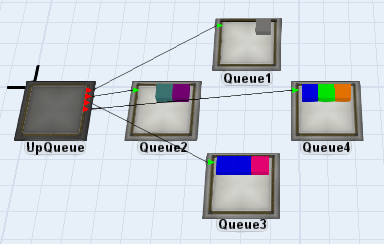
クエリは次のようになります。
Table result = Table.query("SELECT $3 AS Item, $4 AS Step \
FROM $1x$2 AS Items \
WHERE Step > 3",
/*$1*/nrop(node("UpQueue", model())),
/*$2*/outobject(node("UpQueue", model()), $iter(1)),
/*$3*/$iter(2),
/*$4*/getlabel($iter(2), "Step"));
このクエリのresult.cloneTo()の結果は次のとおりです。
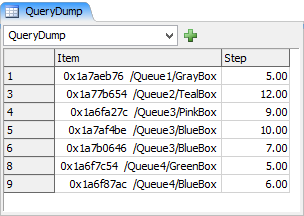
列の参照が下にシフトしました。Itemの参照は$3、Stepラベルの参照は$4です。また、特別なテーブル識別子$1x$2を使用して、2次元モデル構造が1つの仮想テーブルに「フラット化」されています。1つ目の次元は、UpQueueの出力ポートであり、2つ目の次元は、UpQueueの出力ポートに接続された各キューのサブノードツリーです。
テーブルとしての数字
$1では、nrop(node("UpQueue", model())を返します。以前はキューオブジェクト自体に$1を割り当てていましたが、$1は純粋な数字、つまりUpQueueの出力ポートの数として定義されるようになりました。続いて、$1 ($iter(1))の反復も数字になります。
モデル構造の「フラット化」
SQLパーサーが特別な$1x$2テーブル参照を確認すると、$1を評価して$1を、各反復に対して$2を評価することによって、テーブルを「作成」します。この例では、$1を評価し、UpQueueの出力ポートの数である3を返します。次に、1から3まで反復し、それぞれ$2を評価します。最初の反復($iter(1) == 1)で、$2はQueue1: outobject(UpQueue, 1)を返しますoutobject(UpQueue, 1)。そこでエバリュエーターはこれがオブジェクト参照であると判断し、テーブルに1行(Queue1のフローアイテムの数)追加します。その後、$1 ($iter(1) == 2)で次の反復に進みます。$2はQueue2: outobject(UpQueue, 2)を返し、エバリュエーターはテーブルに2行(Queue2のフローアイテムの数)を追加し、これを全テーブルが作成されるまで続けます。実際には、テーブルを「作成」しているわけではありません。これは、合計テーブルサイズと、テーブルのどの行が$反復に関連付けられているかを保存しているだけです。テーブルを作成したら、エバリュエーターはテーブルの各行のクエリを評価し、$3と$4を呼び出して各反復の関連値を調べます。
テーブルを定義する際には、任意の数のモデル構造「ディメンション」を使用してテーブルを定義できます。つまり、$1x$2x$3x$4という、4つのモデル構造の次元またはそれ以上のテーブルを作成できます。標準テーブルの場合と同じように、これらのテーブルに対して内部結合を行うことができます。そのため、これらの高度なクエリ手法を使用すれば、複雑なフィルタリングや優先順位付けを比較的単純なSQLクエリで実現できます。
インデックスを使用する
インデックスは、テーブル内の個々の列に追加可能な内部データです。インデックスを使用すれば、テーブル内の行を列内の値に基づいて検索することができます。
たとえば、次のようなテーブルがあるとします。
| ID | Name | Util |
|---|---|---|
| 1 | Person1 | 23.4 |
| 2 | Person2 | 34.5 |
| 3 | Person3 | 12.3 |
| 4 | Person4 | 78.9 |
| 5 | Person5 | 56.7 |
IDが2の行からNameの値を取得したい場合は、次のようなクエリを作成します。
SELECT Name FROM ExampleTable WHERE ID = 2通常は、ID列に2が入っている行を探すためにクエリでテーブルのすべての行を検索します。テーブルが非常に長かった場合は、このクエリに多くの時間がかかります。しかし、ID列にインデックスを追加して、クエリでそのインデックスを使用すれば、すべての行の値2のチェックを回避することができます。代わりに、インデックスに値が2の行が保存されるため、クエリでインデックスを使用してそれらの行のリストを取得するだけです。このケースでは、その値を持つ行は1つだけです。
複数の値が保存されたグローバルテーブルにインデックスを追加するには、Table.addIndex()メソッドを使用します。他にもクエリに使用可能なオブジェクト(統計コレクターやストレージシステムなど)があるため、それらの列の一部にインデックスを追加することができます。
順序付きと順序なしの2種類のインデックスがあります。選択するインデックスの種類は、テーブルに対して実行するクエリの種類に基づく必要があります。正確な値を検索する(WHERE col = val)場合は、順序なしインデックスの方が適しています。値の範囲を検索する(WHERE col <= val)場合は、順序付きインデックスの方が適しています。
クエリでインデックスを使用すれば、WHEREステートメント(JOIN ONステートメントを含む)のパフォーマンスを向上させることができます。ただし、すべてのWHEREステートメントでインデックスを利用できるわけではありません。下の表で、いくつかのWHEREステートメントを紹介し、それぞれでインデックスを使用する(または使用しない)理由を説明します。すべての例で上のテーブルを使用します。また、以下を前提とします。
- ID列には順序なしインデックスが含まれている。
- Name列にはインデックスが含まれていない。
- Util列には順序付きインデックスが含まれている。
| ステートメント | インデックスの使用 | 説明 |
|---|---|---|
|
あり | ID列に順序付きインデックスが含まれているため、比較は等価比較で、比較する値はテーブル全体で一定で、インデックスを使用できます。 |
|
なし | ID列のインデックスが順序なしのため、インデックスを順序付けに基づく絞り込みに使用することはできません。 |
|
なし | Util列には順序付きインデックスが含まれていますが、テーブル全体で一定ではない値と比較されるため、テーブル全体を検索する必要があります。 |
|
あり | Util列のインデックスは順序付きのため、ここではインデックスを使用できます。 |
|
あり | AND式の少なくとも一方の辺でインデックスを使用できるため、インデックスが使用されます。 |
|
なし | OR式の一方の辺でインデックスを使用できないため、テーブル全体を検索する必要があります。 |
|
あり | OR式の両方の辺でインデックスを使用できるため、テーブル全体を検索する必要がありません。 |
SQL言語サポート
このドキュメントでは、SQLのすべての規則と意味は網羅しません。SQLの非常に役立つチュートリアルを、www.w3schools.com/sql/でご覧いただけます。FlexSimのSQLパーサーは、標準SQL言語構造のサブセットをサポートしています。以下は、FlexSimのSQLパーサーでサポートされているすべてのSQL構造の一覧です。
- SELECT
- FROM
- INNER JOIN
- コンマ区切りの表を使用した内部結合
- ON
- Table.query()コマンドでは、ドル構文を使用してテーブルを定義し、テーブル参照を追加のパラメータとして渡すことができます
- テーブル名を直接定義すると、Table.query()はまずその名前のグローバルテーブルを検索し、次にその名前のグローバルリストを探します。ターゲットリストがパーティション分割されている場合は、SQLテーブル名をListName $1としてエンコードし、最初の追加パラメータとしてパーティションIDをTable.query()に渡す必要があります。または、パーティションIDが文字列の場合は、その文字列を直接テーブル名にエンコードできます。たとえば、テーブル名がListName.Partition1の場合は、「ListName」という名前のグローバルリストと「Partition1」というパーティションIDを使用します。
- ネストされたクエリ
- WHERE
- ORDER BY
- カンマで区切られた複数の基準
- ASC、DESCオプション
- SQL固有のオペレーター
- IN
- コンマで区切られた値を持つIN句
- 値がFlexSim配列であるIN句
- BETWEEN
- AND/OR
- LIKE
- CASE-WHEN-THEN-ELSE-END
- IN
- LIMIT
- ASを使用したSQLエイリアス
- SQL集計関数
- SUM()
- AVG()
- COUNT()
- MIN()
- MAX()
- STD()
- VAR()
- ARRAY_AGG()
- SQL Window関数
- WINDOW句を使用してエイリアス化されたウィンドウ
- OVER()句と任意のPARTITION BY句とORDER BY句OVER()はすべての集計関数をウィンドウ関数にしますが、他のウィンドウ関数では任意です。
- FIRST_VALUE()
- LAST_VALUE()
- LAG()
- LEAD()
- ROW_NUMBER()
- PERCENT_RANK()
- CUME_DIST()
- NTILE()
- SQL関数
- ISNULL(val, replacementVal)
- NULLIF(val1, val2)
- GROUP BY
- HAVING
- その他のSQL関数
- RAND()
- FlexScript式:SQL式内ですべてのFlexScript式を使用できます。ただし、場合によってはカーリーブレースを使用して式をエスケープする必要があります。これはFlexScriptで角括弧[]を使用する場合によく必要とされます。SQLとFlexScriptでは意味が異なるためです。これにより、「WHERE MyCol = Table("MyTable")[1][1]」のような式の解析中にエラーが発生します。この場合、次のようにカーリーブレースを使用してSQL内のFlexScript式をエスケープできます。WHERE MyCol = { Table("MyTable")[1][1] }
- ROW_NUMBER:FlexSimのSQLパーサーには、ROW_NUMBERという名前のハードコードされた列が含まれています。この列は、照会対象のテーブルに関連付けられた行番号を示します。
SQLクエリ結果の取得
テーブルのSQLインターフェイスの詳細については、Table.query()を参照してください。