Key Concepts About Experiments
About the Experimenter and Optimizer
After you've built and successfully validated a current-state model of your business system, you can move on to creating the ideal future-state model. (See Current vs. Future State Models for more information.) The Experimenter and Optimizer tools will help you design, test, and ultimately find the optimal business system.
The Experimenter is a tool that runs the same simulation model multiple times, changing one or more parameters each time to see if the results are different. The Experimenter also includes the Optimizer, which can give you a high-level overview of the conditions that will produce the best possible solution for the problem you are trying to solve through simulation.
For example, you could design an experiment to discover the optimal or minimum number of employees needed at a particular workstation. You could run different experiments with the same simulation model with a varying number of employees at the work station. Then you could compare something such as the utilization rate for the employees and the impact on throughput or delay times. This information would help you to make hiring decisions for your business based on your desired outcomes and priorities.
In this same example, you could also run the Optimizer to find the optimal range of employees versus the optimal number of machines needed for a given process. It could identify several possible solutions to find the optimal balance between two or more trade-offs (such as throughput versus cost).
Key Terms
The following is an explanation of some common terms and important concepts related to the Experimenter:
Experiment
An experiment is a plan for changing parameter values, running the model with those new values, and recording the performance measure values. An experiment can help you understand the way your parameters influence your performance measures.
You could carry out this process manually, by changing parameter values, then running the model, then recording the performance measures. However, this task becomes tedious very quickly. FlexSim can help you plan an experiment, and then FlexSim can carry out that plan for you, recording information from every model run and compiling the results for you.
Parameters
Experiments rely on Model Parameters, which allow you to change various aspects of your model. For example, a parameter might control the number of employees at a station, or the location of various equipment.
Scenario
A scenario is a set parameter values. For example, once scenario might specify that there are two employees at a station, and a specific equipment layout. Another scenario might specify that there are four employees at a station, with a different layout.
The following image shows the same example used in the preceding section:

Each scenario is defined in a separate column. In this example, the Experimenter will test 5 different scenarios, or five combinations of parameter values. Each scenario defines a different position for Processor2 and Processor3. Notice that this experiment doesn't include one of the model parameters. This is perfectly acceptable; you can focus only on the parameters you need.
Replication
A replication is a single run of a simulation model for a specific scenario. If desired, you can decide to run only one replication of a given scenario, but it would probably be better to run multiple replications to get more accurate statistical data.
Your simulation model likely has a few different points at which it uses random numbers to create variability in the system. Each time the Experimenter runs a replication of a particular scenario, it will use a specific number stream to generate any random numbers that are required by the simulation model. For example, the Experimenter will use a specific random number stream if the simulation model requires flow items to arrive in random intervals or if a particular process takes a random amount of time to complete.
Each replication will have slightly different results because each one will use a different number stream to generate random numbers. The more replications you run, the more your results will be statistically reliable because predictable patterns will start to emerge.
The following image shows an example of what an experiment looks while it's being run:
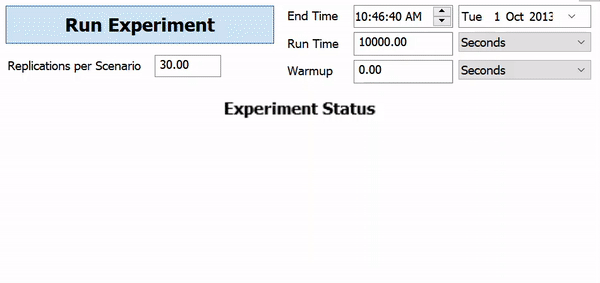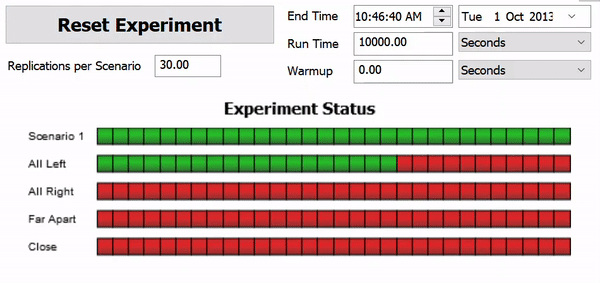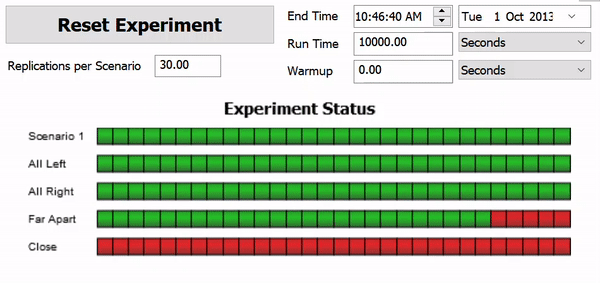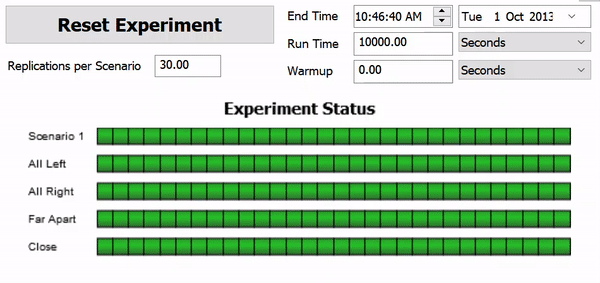
In this example, the Experimenter is running 30 replications of the five different scenarios. Each scenario is testing one a different model layout for the distances between two processors. Each scenario is being run 30 times, changing the replication number each time. This allows you to see not only the overall performance of the scenario, but how sensitive each scenario is to variations in random numbers.
The experiment will subject all scenarios to the same random numbers, so that comparing between scenarios makes sense. In the above example, all five scenarios are run using the random numbers for Replication 1. All five scenarios are also run using the random numbers for Replication 2 and so on.
Performance Measures
The Experiment uses all the Performance Measures defined in the model. For each replication of each scenario, the Experimenter will record the value of all performance measures. Once all replications have completed, the Experimenter will report the average values for each scenario.
Best Practices
The following sections explain a few best practices to keep in mind when designing experiments:
Make Sure Your Model Was Built With Good Data Inputs
You need to ensure that you put good data into your model (inputs) in order to get good data out of your model (outputs). Make sure that your simulation model relies on accurate data and random number distributions that accurately represent your business system's requirements. (See Data Gathering Strategies for more information.)
Validate Your Model to Reduce Errors
Try running your simulation model at least one time from start to finish before you run an experiment. Once your simulation model can be run without any errors, you are ready to use the Experimenter.
Know Your Computer's Memory Limits
The more experiments or optimizations you run, the more memory it will require from your computer. The Experimenter and Optimizer will use all your cores unless you limit the number of cores on the Advanced tab. You might begin to experience problems if you are using lots of cores. Each core requires as much memory as a single model run. For example, using 8 cores means that it would require 8 times as much memory as a normal model run.
For that reason, make sure you are familiar with your computer's capabilities. Design your experiments that your computer can handle without causing an overload or taking longer than you wanted it to take. Running more experiments and optimizations can increase your confidence in the results you are getting, but you need to weigh the need for good data against your computer's capabilities.
Optimization in FlexSim
The following sections explain a few of the important key concepts and caveats to keep in mind when using the Optimizer.
Finding the Optimal Solution
The Optimizer's goal is to find a optimal solution, or a configuration of your model's parameters that optimize the performance measures. It searches using a proprietary combination of optimization algormithms. For example, it may use a genetic algorithm, or a particle swarm algorithm, or some other algorithm. By using a combination of algorithms, the optimizer can find better solutions faster.
It is important to remember, however, that while it would be ideal to find the absolute best set of parameter values for a model, it's usually impossible. The longer you let the optimizer search, the more likely it is that the optimizer will find a really good solution. But without running every single combination of parameters, there is no guarantee that you have found the very best combination. It could be that if you let the optimizer continue its search, it may find a better solution.
Multi-Objective Optimization
The optimizer allows you to specify more than one objective function. If you do, then the optimizer will run a multi-objective optimization. In this case, you will not get a single best solution. Instead, you will get a set of solutions, where each solution counts as an optimal solution.
For example, suppose you are optimizing the number of employees in a facility. More employees can increase revenue, but they also increase the cost of running the facility. If you optimize by maximizing revenue, but also minimizing cost, you might see a chart like this in the optimizer:
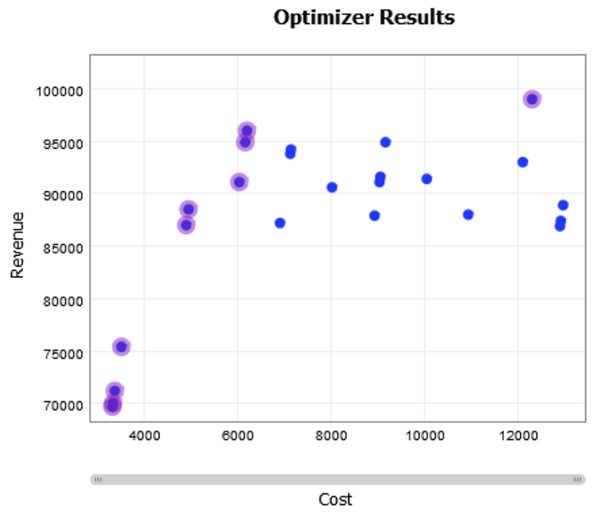
This chart shows the optimal solutions highlighted in purple. For all the non-purple solutions, there is a purple solution that has both a lower cost and a higher revenue. The purple solutions are considered optimal because no other solutions have been found that show an improvement in all objectives; choosing another solution will allow you to improve one objective at the expense of another.
In this example, the purple solutions show the best revenue you can get for a given cost. To choose a blue solution would mean choosing a more expensive and less effective solution. Also, there are some purple solutions that might not be worth it; the highest-cost solution is very high cost, and doesn't improve revenue very much over the second-highest-cost solution. Running with multiple objectives allows you to understand how the variables trade off across the whole space, allowing you to choose a sensible trade-off option.
Starting the Search with Good Solutions
By default, the optimizer will start the search by choosing arbitrary solutions. However, you can tell the optimizer to begin its search using the scenarios shown in the Scenarios tab. In most cases, this can help reduce the time it takes the optimizer to find an acceptable solution.