The Reinforcement Learning Tool
Overview and Key Concepts
The Reinforcement Learning tool enables you to configure your model to be used as an environment for reinforcement learning algorithms.
When a reinforcement learning algorithm launches FlexSim in order to train an agent, it communicates with this tool using sockets. This tool is designed to follow a particular socket protocol for handling each function in a custom reinforcement learning environment.
For more information and steps to get started, see Key Concepts About Reinforcement Learning.
A model may contain multiple Reinforcement Learning tool objects. When training, only the first Reinforcement Learning tool object will be used to learn. The others will execute the On Request Action trigger to make random, heuristic, or trained decisions at the specified events. You can use the right-click Move Up option in the Toolbox pane in order to reorder the Reinforcement Learning objects in your model.
The Settings Tab
The Settings tab has the following properties:
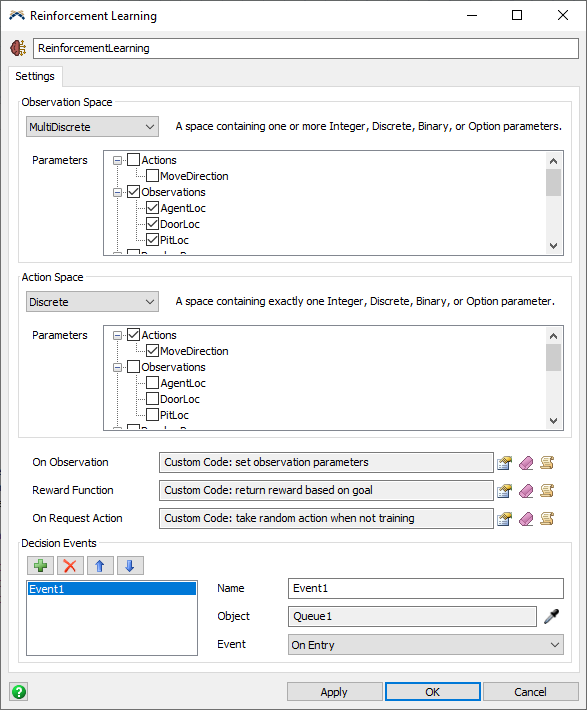
Observation Space
The Observation Space configures the set of parameters that are used as input states to the reinforcement learning algorithm. Before beginning training, the algorithm needs to know the range of available inputs in order to learn how those states correspond to received rewards for taking actions.
The following spaces types are available:
- Box - A space containing one or more Continuous parameters. Each continuous parameter has a defined minimum and maximum value.
- Discrete - A space containing exactly one Integer, Discrete, Binary, or Option parameter. Each of those parameter types has a specific range of possible values. In the algorithm, each value will be re-mapped to values starting at 0 regardless of their bounds. For example, a Discrete parameter with a lower bound of 10, an upper bound of 12, and a step size of 0.5 will map the possible values of [10, 10.5, 11, 11.5, 12] to [0, 1, 2, 3, 4, 5] for the algorithm.
- MultiDiscrete - A space containing one or more Integer, Discrete, Binary, or Option parameters. Each parameter will be remapped as described in Discrete above.
- MultiBinary - A space containing more than one Binary parameter. Each binary parameter will be true (1) or false (0).
- Bonsai - A space compatible with the Bonsai platform. When using Bonsai, both the Observation Space and Action Space must be set to this option.
- Custom - A space defined by a custom string and callback. If you have customized your environment to handle additional space types, this option enables you to specify a particular string for FlexSim to return as the space definition. It will also execute the Get Observation callback, which should return a Variant (such as a particular value, an Array, or a Map), which will be converted to JSON and sent to the reinforcement learning algorithm when an observation is requested.
Action Space
The Action Space configures the set of parameters that are used as the potential actions that an agent can take after an observation. Before beginning training, the algorithm needs to know the range of available actions in order to learn how those actions correspond to received rewards for an observed state.
The Action Space contains the same options as the observation space above, specifying an action as a set of parameters with constrained ranges of possible values.
For a Box action space, parameters will be normalized to a range between -1 and 1 for the algorithm. The action values sent from the algorithm will be remapped to the proper bounds when setting the action parameters in the model.
For a Custom action space, the Take Action callback receives a string describing the action that should be taken, and the callback code can then parse that string and take the appropriate action.
Triggers
The following triggers are used by the Reinforcement Learning tool:
- On Observation - This trigger is executed just before an observation. You can use this trigger to set the observation parameters just before they are returned. This trigger is optional. If other code sets the observation parameters, then this trigger can do nothing.
- Reward Function - This trigger must return an array with 2 elements. The first element is a number value specifying a reward amount. The second element is a 1 or a 0 specifying whether the training episode is done. This function must be implemented in order to use the model as a training environment. When training, the results of this trigger will be passed to the algorithm. When running regularly, the results will be passed to the On Request Action callback.
- On Request Action - This trigger will fire when the model is running regularly, not when training. This trigger fires at the moments when an action is requested. While training, the reinforcement learning algorithm provides the actions. When not training, this trigger provides the actions. You can use this trigger to either use a random function, a heuristic function, or a trained agent to determine an action for the current state of the model. Use this trigger to set the action parameters.
Decision Events
When the model is reset, an initial observation and action will be taken. The model will then run. At each of the specified decision events, a reward will be received for the previous actions, and if the episode is not done, another observation and action will be taken. This cycle will continue until the Reward Function returns that the episode is done.
The logic for returning a reward, making an observation, and taking an action will happen immediately before the specified event. You can specify the important events where a decision needs to be made, and this object will set the action parameters just before that event is executed so that you can use those action parameters within the event.
In addition to specifying decision events, you can also request a decision at a particular moment by using custom code. The reward, observation, and action will all happen immediately inline during that function. You can then use the action parameters immediately after the function.
requestdecision("ReinforcementLearning1");
The Bonsai Tab
The Bonsai tab is used when connecting FlexSim and Bonsai. For more information on using Bonsai with FlexSim, see Getting Started with Bonsai.
The Bonsai tab has the following properties:
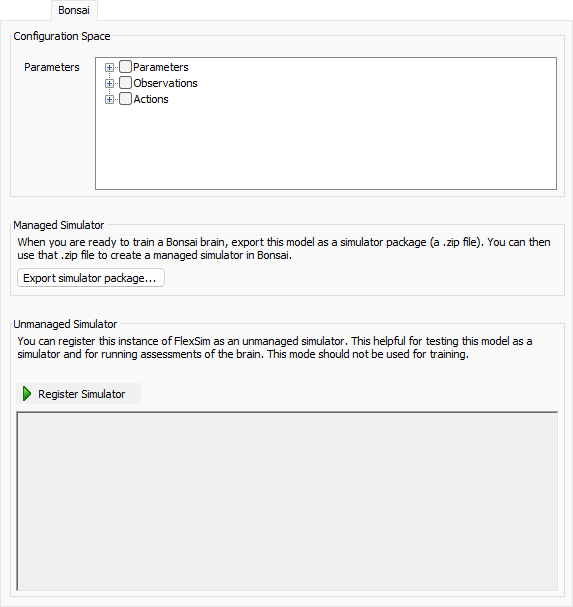
Configuration Space
Some Bonsai brains specify a configuration. Use this area to select the parameters that included in the configuration.
Managed Simulator
This area helps you create a managed simulator in Bonsai. Click the Export simulator package... to save the model as a .zip file. You can then upload that .zip file to Bonsai as part of making a managed simulator.
Unmanaged Simulator
This area helps you use FlexSim as an unmanaged simulator. Click the Register Simulator to register the current instance of FlexSim as an unmanaged simulator. Once registered, this area shows the communication between FlexSim and Bonsai, and the Unregister Simulator button appears.
- Configuration Space -
- - Use this button to save the model as a .zip file that can be uploaded to Bonsai to create a managed simulator.
- Register Simulator - Use this button to register the current instance of FlexSim as an unmanaged simulator. If registration succeeds, this button will become the Unregister Simulator button.