Lists Functional Reference
Overview and Key Concepts
Lists (which are also sometimes referred to as global lists) are a tool that can be used to create more complex flows between 3D objects and process flows.
Values and Pullers
In this and other documentation, we often use the terms value or value object and puller or puller object. These terms have special meaning in relation to the list. Whenever you push something onto a list, an entry is created on the list that contains a primary value, which is the value that was pushed onto the list. For example, you push flow items onto an Item List. Each item pushed onto the list will have its own entry. The primary "value" of each entry is therefore the item that is associated with that entry. Values may be strings or numbers, but more often they are objects like flow items. Thus when we say value object we are assuming that the primary value of an entry is in fact an object reference, like a flow item.
Likewise, each back order has a primary "value" associated with it, although in order to avoid confusion, we call this the "puller". Like with list entry values, back order pullers can be either numbers or strings, but usually they are object references, so we use the term puller object when we assume that a puller is an object. In the example of an Item List, fixed resources are usually the "puller objects" who are pulling from an item list trying to find which item to receive next.
Pulling
When you pull from a list, you query the list for entries. The most basic pull defines only a number of entries to pull with out regard to what the values of those entries are. SQL queries can be added to your pull in orderto pull specific values from the list, possibly in a specific order. See the Query Syntax section below for information on how to write queries.
Often you want to pull a specific object or node from the list. This can be accomplished using two different methods. The first is by using a WHERE clause. For example:
WHERE value = Model.find("MyObject")
List("List1").pull("WHERE value = Model.find(\"MyObject\")")
The second method is to skip the SQL and pass a reference to the object directly.
List("List1").pull(Model.find("MyObject"))
This method of pulling can be especially useful when pulling flow items and other objects that move through the model. If a back order is created, a path to the object/node will be displayed under the query column.
Query Syntax
In a pull request you may include an SQL query that filters and prioritizes what you want to pull from the List. The query usually will include a WHERE, and/or ORDER BY clause. In some special cases you may use the SELECT clause. It has a special meaning that will be explained later in this topic.
WHERE queueSize < 5 ORDER BY age ASC
This reference documents only information specific to FlexSim's SQL implementation. Refer to commonly available documentation for more general information on the language.
Using List Fields
By default, when you reference a field in a WHERE or ORDER BY clause, it will refer to one of the defined fields on the List.
ORDER BY pushTime
Here, the ORDER BY clause will prioritize by the List's pushTime field in ascending order (in SQL the default is ascending), assuming the pushTime field is a defined field on the List.
Accessing Labels
If a field that you define in your SQL query is not a defined field on the List, then the query will retrieve the label value of the same name on the entry's value object.
WHERE SKU = "05692AQD"
In this example, if SKU has not been defined as a field on the List, and let's say it is an Item List, the query will retrieve the label named "SKU" on the items that have been added to the List, and compare it against "05692AQD".
Puller and Value Table Specifiers
You can also access labels on the puller object using a keyword "Puller" table specifier, followed by a dot.
WHERE step = Puller.step
Here the step field (either a defined List field or a label on the value object) is compared with the step label on the puller object. Here we use "table specifier" in reference to SQL's syntax for accessing a database table. You might conceptualize the List as a database table with the name "Value", and you are kind of doing an inner join with a table with one row in it called Puller, where the labels on the puller object are like fields of the Puller table.
By default if you leave a table specifier out, it assumes it is a defined field on the List or a label on the value object. However you can use a keyword "Value" table specifier explicitly for better readability.
WHERE Value.step = Puller.step
Here you can either use lower case value or upper case Value, and lower case puller or upper case Puller, according to your preference. Here at FlexSim we usually capitalize the table and lower-camel-case the fields.
Using FlexScript Commands in SQL Queries
You can also use FlexScript Commands in your SQL queries.
ORDER BY round(distance / 100) ASC, age DESC
This ORDER BY clause takes the distance field and categorizes it into distance ranges 100
units wide, so that a distance of 130 would be tied with a distance of 95
(round(130 / 100) == round(95 / 100), but would get higher priority than a
distance of 200 (round(130 / 100) < round(200 / 100)). Ties would then use the
second priority clause and be prioritized by highest age.
Using the SELECT clause
When pulling from lists with a query, the SELECT clause takes on a special meaning. It allows you to pull things from the list using fluid-like request quantities, instead of discrete entries on the list. Take for example the following listpull() command usage.
listpull("DoughBins", "SELECT kg", 4.5, 4.5)
And assume that the entries on the DoughBins list look like the following when pulled.
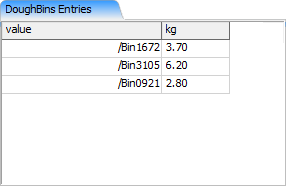
Here, instead of trying to pull a number of discrete entries from the list, the listpull() command is trying to pull 4.5 total kg units from the list, no matter how many discrete entries it requires. In this case, the pull operation will pull the full 3.7 kg from Bin1672. Next, it will pull the remaining 0.8 kg from Bin3105. The listpull() command will then return back an array consisting of both Bin1672 and Bin3105.
Overflow Management
This example naturally leads to the question of how the list manages left over amounts, namely the remaining 5.4 kg on Bin3105. And what does the list do about removing entries from the list? Obviously it should remove Bin1672 from the list because it has pulled its full kg amount. But what should it do about Bin3105, which technically has some "overflow" that hasn't been pulled off the list. Should it remove Bin3105 from the list or leave it on? The answer to that depends on the nature of the fields that you are querying in the SELECT clause.
Trackable Overflow
The list will track overflow amounts if the field defined in the SELECT clause meets one of the following requirements.
- The clause references a dynamic label field.
- The clause references a label that is not explicitly defined as a field on the list.
- The clause references a non-dynamic field.
If one of these requirements is met, the list will track the values of the fields, decreasing them until they are 0, at which point it will remove the entries from the list. If labels are used (options 1 or 2), then as the pull operation finds valid entries to pull, it will decrement the value of the label by the amount that is pulled. So in this example, the kg label on Bin1672 will be decremented to 0 and Bin1672 will thus be removed from the list. Then the kg label on Bin3105 will be decremented to 5.4, and since it is still greater than 0, it will remain on the list. Subsequent pull operations will pull from the list with Bin3105's kg quantity properly decreased.
When non-dynamic fields are used (option 3), the list stores its own cached value for the field, so the pull operation will decrement its own cached value as quantities are pulled from the list. Admittedly this makes the term "non-dynamic" a bit of a misnomer because the values do change while on the list. In this case, think of the fields instead as "cached" or "non-reevaluated" fields.
Untrackable Overflow
SELECT clauses where the list does not manage overflow amounts include the following:
- The clause references a dynamic non-label field.
- The clause is an SQL expression that does not reduce to a single field, i.e.
SELECT length * width.
When SELECT clauses with untrackable overflow are used, any entries containing overflow amounts will be removed from the list when they are returned. This means that in the above example, Bin3105 will be removed from the list, even though it technically has 5.4 kg left over.
SELECT Clause Constraints
In list pull operations, the SELECT clause should reference only one "column". In other words, it should not be a comma-separated list of columns like normal SQL queries. Additional columns will be ignored.
Using Lists in the query() Command
You can also integrate global lists in sql queries in the query() command. Just include the List as a table named in the FROM clause, and then access its fields normally. Note that here you should not use puller-dependent fields. If it is a partitioned list, then you should encode the table name as ListName.$1, and then pass the partition ID as the first additional parameter to query(). Or, if the partition ID is a string, you can encode the string directly into the table name. For example, the table named ListName.Partition1 means it will use the global list named "ListName", and the partition with ID "Partition1".
Events
You can listen to values being pushed an pulled from the list with the OnPush and OnPull events.
On Push
On Push occurs whenever a value is pushed on the list.
It has the following parameters:
| Event Parameter | Type | Explanation |
|---|---|---|
| Value | Variant | The value that was pushed on to the list |
| Partition ID | Variant | The partition the value was pushed on to |
| Result | Variant | The list entry entity, if the value was not immediately pulled. |
On Pull
On Pull occurs whenever an object attempts to pull a value from the list.
It has the following parameters:
| Event Parameter | Type | Explanation |
|---|---|---|
| Query | string | The query passed in to the listpull command |
| Request Num | double | The request number passed in to the listpull command |
| Require Num | double | The require num passed in to the listpull command |
| Puller | Variant | The object passed in to the listpull command |
| Partition ID | Variant | The partition passed in to the listpull command |
| Flags | int | The pull flags passed in to the listpull command |
| Result | Variant | The list backorder, if the backorder was not immediately fulfilled |
Statistics
The list keeps the following statistics:
| Statistic | Description | Updated |
|---|---|---|
| Input | The total number of values pushed to the list | Push |
| Output | The total number of values pulled from the list | Pull |
| Content | The total number of values currently on the list | Push/Pull |
| Staytime | The total time each value spent on the list | Pull |
| Backorder Input | The total number of backorders created on this list | Pull (if the value cannot be pulled immediately) |
| Backorder Output | The total number of fulfilled backorders | Push (if the push fulfills a backorder) |
| Backorder Content | The current number of backorders that have not been fullfilled | Push/Pull (if a backorder is created or fulfilled |
| Backorder Staytime | The time each backorder spends waiting to be fulfilled | Push (if the push fulfills a backorder) |
In addtion, the list keeps the above 8 statistics for each individual partition. The name of the statistic simply has the word "Partition" appended to the front (Partition Input, Partition Staytime, Partition Backorder Output, etc.).