強化学習ツール
概要と主要な概念
強化学習ツールを使用すると、強化学習アルゴリズム用の環境として使用するようにモデルを構成することができます。
強化学習アルゴリズムは、エージェントをトレーニングするためにFlexSimを起動すると、このツールとソケットを使用して通信します。このツールは、カスタム強化学習環境で各関数を処理するための特別なソケットプロトコルに従うように設計されています。
開始方法と手順の詳細については、「強化学習に関する主要な概念」を参照してください。
モデルには、複数の強化学習ツールオブジェクトを含めることができます。トレーニング中は、1つ目の強化学習ツールオブジェクトのみが学習に使用されます。他のオブジェクトは、On Request Actionトリガーを実行して、指定されたイベントでランダムな、ヒューリスティックな、またはトレーニングされた決定を下します。[ツールボックス]ペインで右クリックの[上に移動]オプションを使用して、モデル内の強化学習オブジェクトを並べ替えることができます。
[設定]タブ
[設定]タブには次のプロパティがあります。
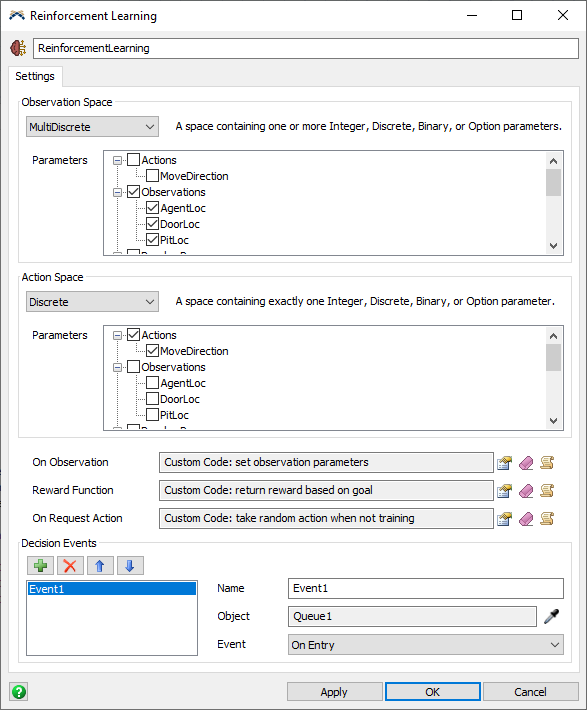
監視スペース
監視スペースは、強化学習アルゴリズムへの入力状態として使用されるパラメータのセットを構成します。トレーニングを始める前に、アルゴリズムは、使用可能な入力の範囲を認識して、それらの状態がアクションの実行に対して受け取る報酬にどのように影響するかを学習する必要があります。
次のスペースタイプを使用できます。
- ボックス - 1つまたは複数の連続したパラメータを含むスペース。連続パラメータごとに、最小値と最大値が定義されます。
- 離散 - 整数、離散、バイナリ、オプションのいずれか1つのパラメータを含むスペース。そのようなパラメータタイプのそれぞれに使用できる特定の値の範囲が設定されます。アルゴリズムでは、各値がそれぞれの境界に関係なく0から始まる値に再マッピングされます。たとえば、下限が10、上限が12、およびステップサイズが0.5の離散パラメータは、使用可能な値の[10, 10.5, 11, 11.5, 12]をアルゴリズムの[0, 1, 2, 3, 4, 5]にマッピングします。
- 複数離散 - 整数、離散、バイナリ、オプションのいずれか1つまたは複数のパラメータを含むスペース。各パラメータは、上の「離散」で説明したように再マッピングされます。
- 複数バイナリ - 1つまたは複数のバイナリパラメータを含むスペース。各バイナリパラメータがtrue(1)またはfalse(0)になります。
- カスタム - カスタム文字列とコールバックで定義されたスペース。追加のスペースタイプを処理するように環境をカスタマイズした場合は、このオプションを使用すると、FlexSimがスペース定義として返す特別な文字列を指定することができます。Get Observationコールバックも実行します。これにより、観察が要求されたときにJSONに変換され、強化学習アルゴリズムに送信されるバリアント(特別な値、配列、マップなど)が返されるはずです。
アクションスペース
アクションスペースは、エージェントが観察後に取得可能な、潜在的なアクションとして使用されるパラメータのセットを構成します。トレーニングを始める前に、アルゴリズムは、使用可能なアクションの範囲を認識して、観察された状態に対して受け取る報酬とそれらのアクションの対応関係を学習する必要があります。
アクションスペースには、前述の観察スペースと同じオプションが含まれています。これらのオプションでは、使用可能な値の範囲が制限されたパラメータのセットとしてアクションを指定します。
ボックスアクションスペースの場合は、パラメータがアルゴリズムの-1~1の範囲に正規化されます。アルゴリズムから送信されるアクション値は、モデルにアクションパラメータが設定されたときに適切な範囲に再マッピングされます。
カスタムアクションスペースの場合は、Take Actionコールバックが実行すべきアクションに関する文字列を受け取り、その後で、コールバックコードがその文字列を解釈して、適切なアクションを実行できます。
トリガー
次のトリガーが強化学習ツールによって使用されます。
- On Observation - このトリガーは観察の直前に実行されます。このトリガーは、返される直前に観察パラメータを設定するために使用できます。このトリガーはオプションです。他のコードが観察パラメータを設定した場合は、このトリガーは何もしません。
- Reward Function - このトリガーは、要素が2つの配列を返す必要があります。1つ目の要素は、報酬額を示す数値です。2つ目の要素は、トレーニングエピソードが完了したかどうかを示す1または0です。この関数は、トレーニング環境としてモデルを使用する場合に実装する必要があります。トレーニング中に、このトリガーの結果がアルゴリズムに渡されます。定期的に実行する場合は、結果がOn Request Actionコールバックに渡されます。
- On Request Action - このトリガーは、モデルがトレーニング中ではなく定期的に実行される場合に発動します。このトリガーは、アクションが要求された直後に発動します。トレーニング中は、強化学習アルゴリズムがアクションを提供します。トレーニング中でない場合は、このトリガーがアクションを提供します。このトリガーは、ランダム関数、ヒューリスティック関数、またはトレーニングされたエージェントを使用して、モデルの現在の状態に対するアクションを決定するために使用できます。このトリガーを使用して、アクションパラメータを設定します。
決定イベント
モデルがリセットされた場合は、初期観察とアクションが実行されます。その後で、モデルが実行されます。指定された決定イベントごとに、前のアクションに対する報酬が受け取られ、エピソードが完了しなかった場合は、別の観察とアクションが実行されます。このサイクルは、Reward Functionからエピソードが完了したことが返されるまで繰り返されます。
指定されたイベントの直前に、報酬を返して、観察し、アクションを実行するロジックが起動します。決定を下す必要がある重要なイベントを指定できるうえ、このオブジェクトはイベントが実行される直前にアクションパラメータを設定するため、イベント内でこのようなアクションパラメータを使用できます。
決定イベントの指定に加えて、カスタムコードを使用して特定の時点で決定を要求することもできます。報酬、観察、およびアクションはすべて、その関数中に即座に順番に起動します。その後で、関数の直後にアクションパラメータを使用できます。
requestdecision("ReinforcementLearning1");