Using a Trained Model
Using a Trained Model
Once you have a trained reinforcement learning model, then you are ready to evaluate the performance of the AI's decisions in your simulation environment and then use the trained AI model in a real production environment. As part of getting started, you should have downloaded the included python scripts and configured an environment to run them. Now, we will modify and use those scripts to demonstrate using a trained model in response to HTTP requests, which can originate from a real system or from our simulation model. The process of using a trained machine learning model to make a prediction is known as inference.
Hosting an Inference Server
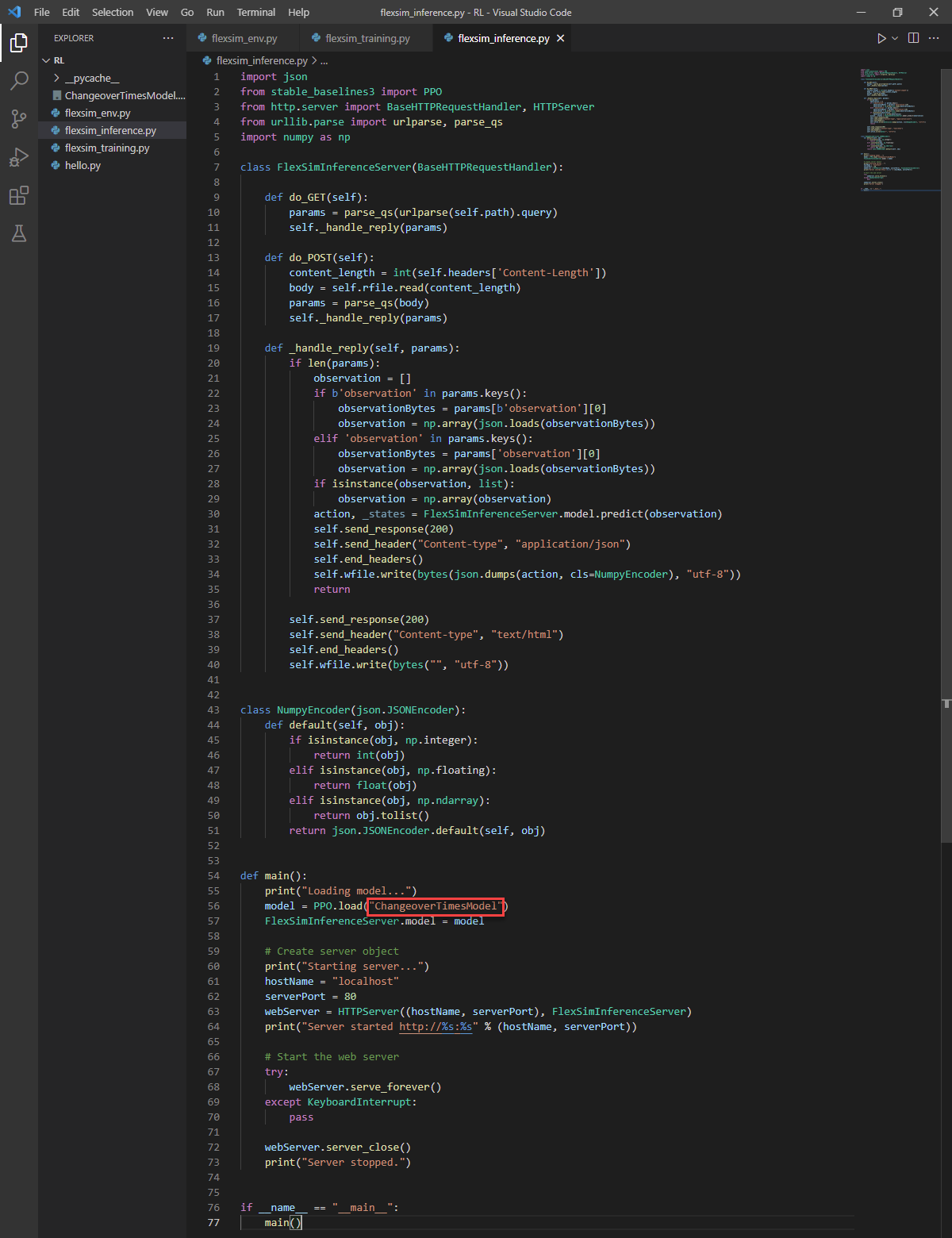
The flexsim_inference.py script contains the definition for a FlexSimInferenceServer class that inherits from BaseHTTPRequestHandler. It also contains a main() function that demonstrates loading a trained model and starting an HTTP server that uses the FlexSimInferenceServer class to respond to queries to make a prediction using the loaded AI model. This server is a simple example for demonstration purposes and not recommended for production. You should implement a more secure server for live systems.
- In the flexsim_inference.py script, modify the model load name to the name used when training: "ChangeoverTimesModel"
- Run the flexsim_inference.py script by pressing the Run Python File button at the top.
- The python script should print that it is loading the model and starting the server.
- In a web browser, navigate to localhost:80/?observation=3
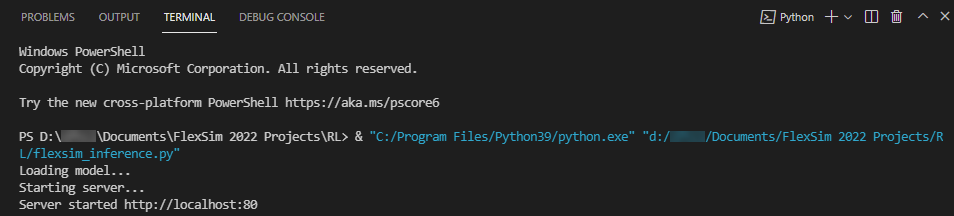
This should query the server and return a value between 0 and 4. It should usually return 3.
Using the Server in the FlexSim Model
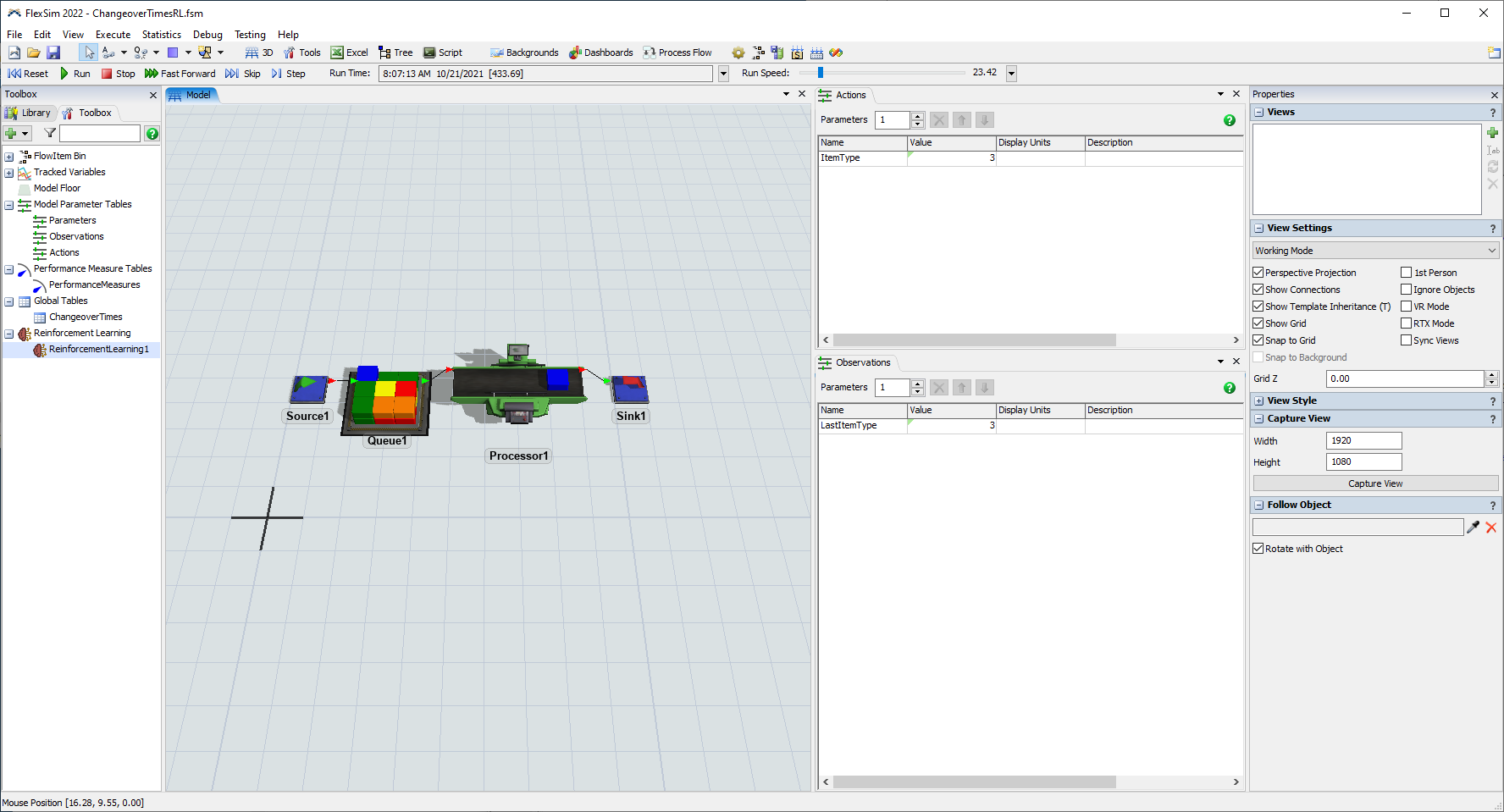
- If it is not already open, reopen the ChangeoverTimesRL.fsm model in FlexSim.
- In the Toolbox pane, double-click ReinforcementLearning1 to open its Properties.
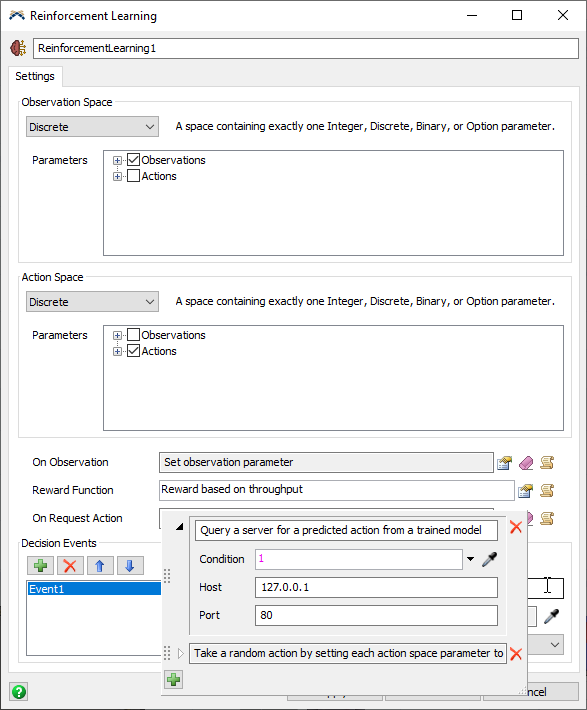
- In the On Request Action trigger, add the option to Query a Server for an Action and drag it above the random action option. This way, it will first try to query the server for an action, but it will take a random action is the server is unavailable. You can modify the Condition if you want to be able to enable or disable the model from trying to communicate with the server.
- Click on the OK button to apply your changes and close the window.
- Ensure that your python inference server is still running. If you stopped it, start it again.
- Reset and Run the model. The model should now query the server with an observation, receive a predicted action, and use that action when pulling each item. You should see the ItemType parameter set to predicted values that try to minimize the changeover times by pulling matching itemtypes when possible.